Gemma 4 是什么,怎么用?Google 最新开源模型完整指南
Gemma 4 是 Google DeepMind 于 2026 年 4 月发布的新一代开源大模型系列,专为多步骤规划和自主 Agent 工作流设计。与上一代不同,Gemma 4 全系列原生支持多模态(文本+图像,部分型号支持音频和视频),提供从边缘设备到服务器的四款模型,最大模型 31B 在 AIME 2026 数学竞赛中达到 89.2%,在 MMLU Pro 上达到 85.2%,整体性能达到同等规模开源模型的前沿水准。所有模型采用 Apache 2.0 协议,可免费商用。
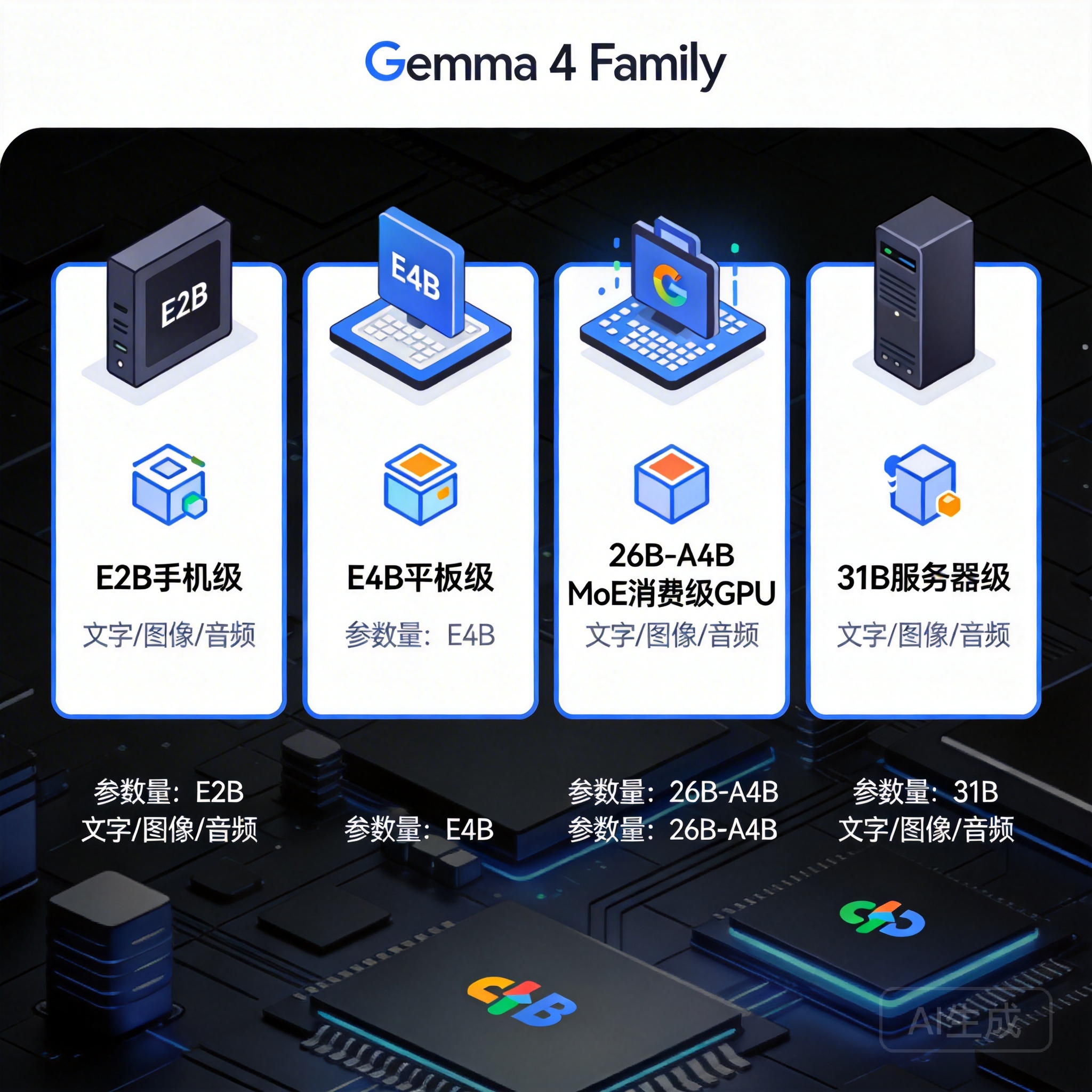
Gemma 4 有哪些版本?四款模型一览
Gemma 4 推出了四款面向不同硬件场景的模型,命名方式有所变化:E 系列代表边缘设备(Edge),A 系列代表 MoE 稀疏激活(Active 参数),数字代表有效/活跃参数量。
关键设计逻辑:
● E2B / E4B:采用 Per-Layer Embeddings(PLE)技术,每个解码层配备独立嵌入,最大化参数效率;是系列中唯一原生支持音频的版本
● 26B-A4B(MoE):总参数 25.2B,推理时仅激活 3.8B,速度接近 4B 模型,性能接近 31B 模型,是性价比最高的选项
● 31B(Dense):密集型架构,全量参数推理,基准成绩最强
Gemma 4 核心能力:远超上代的多模态 Agent
Gemma 4 的发布主题是"将前沿 Agent 能力带到边缘设备",核心能力分为以下几类:
推理与思维链
所有 Gemma 4 模型均内置可配置思维模式,通过 enable_thinking=True 参数开启:
● 数学推理:31B 在 AIME 2026(无工具)中达 89.2%,26B-A4B 达 88.3%
● 代码能力:31B 在 LiveCodeBench v6 中达 80.0%,Codeforces ELO 为 2150
● 科学推理:31B 在 GPQA Diamond 中达 84.3%
视觉理解
31B 和 26B-A4B 支持图像+文本多模态,能力覆盖:
● 物体检测、图表理解、屏幕 UI 识别
● 文档 / PDF 解析、OCR(支持 140+ 语言)、手写识别
● 支持可变分辨率(Token 预算:70 / 140 / 280 / 560 / 1120),低预算适合分类,高预算适合 OCR
音频处理(E2B / E4B 专属)
轻量边缘模型是 Gemma 4 中唯一支持音频的版本,能力包括:
● 自动语音识别(ASR),最长 30 秒音频
● 跨语言语音翻译
视频理解(全系列)
通过处理帧序列分析视频内容,最长支持 60 秒视频,适合视频摘要、动作识别等任务。
函数调用(Function Calling)
全系列原生支持结构化工具调用,是 Agent 工作流的基础能力,可配合 LangChain、LlamaIndex 等框架直接使用。
怎么用 Gemma 4?四种接入方式
方式一:Transformers(本地部署,推荐)
安装依赖:
pip install -U transformers torch accelerate
文本对话(基础用法):
from transformers import AutoProcessor, AutoModelForCausalLM
MODEL_ID = "google/gemma-4-31B-it" # 或 E4B-it / 26B-A4B-it
processor = AutoProcessor.from_pretrained(MODEL_ID)
model = AutoModelForCausalLM.from_pretrained(
MODEL_ID, dtype="auto", device_map="auto"
)
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "解释一下 MoE 架构的优势"},
]
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
inputs = processor(text=text, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=1024,
temperature=1.0, top_p=0.95, top_k=64)
response = processor.decode(outputs[0], skip_special_tokens=False)
开启思维链推理模式:
text = processor.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # 新增参数,让模型展示推理过程
)
图像理解(需额外安装 torchvision):
pip install -U transformers torch torchvision accelerate
from transformers import AutoProcessor, AutoModelForMultimodalLM
model = AutoModelForMultimodalLM.from_pretrained(
"google/gemma-4-31B-it", dtype="auto", device_map="auto"
)
messages = [{
"role": "user",
"content": [
{"type": "image", "url": "https://example.com/chart.png"},
{"type": "text", "text": "解读这张图表的数据趋势"}
]
}]
inputs = processor.apply_chat_template(
messages, tokenize=True, return_dict=True,
return_tensors="pt", add_generation_prompt=True
).to(model.device)
outputs = model.generate(**inputs, max_new_tokens=512)
response = processor.decode(outputs[0], skip_special_tokens=False)
processor.parse_response(response)
音频处理(仅 E2B / E4B):
pip install -U transformers torch librosa accelerate
model = AutoModelForMultimodalLM.from_pretrained(
"google/gemma-4-E4B-it", dtype="auto", device_map="auto"
)
messages = [{
"role": "user",
"content": [
{"type": "audio", "audio": "https://example.com/speech.wav"},
{"type": "text", "text": "请转录这段音频"}
]
}]
方式二:Ollama(最简单,一行命令)
# 轻量边缘版(本地笔记本)
ollama run gemma4:e4b
# MoE 高效版(消费级 GPU)
ollama run gemma4:26b
# 最强版
ollama run gemma4:31b
Ollama API 调用:
curl http://localhost:11434/api/chat \
-d '{
"model": "gemma4:e4b",
"messages": [{"role": "user", "content": "你好"}]
}'
方式三:Hugging Face Inference API(云端免部署)
在 huggingface.co/google/gemma-4-31B-it 页面直接调用 Inference API,或通过以下方式:
from huggingface_hub import InferenceClient
client = InferenceClient(model="google/gemma-4-31B-it", token="<YOUR_HF_TOKEN>")
response = client.chat_completion(
messages=[{"role": "user", "content": "什么是 Mixture of Experts?"}]
)
print(response.choices[0].message.content)
方式四:Google Kaggle / Vertex AI
Gemma 4 可在 Kaggle(免费 GPU 配额)和 Google Cloud Vertex AI 上直接部署,适合不想配置本地环境的团队,支持企业级权限管理和 SLA。
硬件选择指南
在本地运行 Gemma 4 前,需要确认硬件能否承载目标模型:
内存估算规则:
● FP16 权重:参数量(B)× 2 GB(31B ≈ 62 GB)
● INT8 量化:参数量(B)× 1 GB(31B ≈ 31 GB)
● 26B-A4B 因为只激活 3.8B 参数,实际推理内存接近 8B 模型
量化版本:社区已提供 GGUF 量化版本(unsloth、bartowski 等),可在 Hugging Face 搜索 gemma-4 GGUF 获取,通过 llama.cpp 或 LM Studio 在 CPU 上运行低显存量化版本。
Gemma 4 vs Gemma 3:升级了什么
常见问题
Q:Gemma 4 可以商用吗?
可以。Gemma 4 采用 Apache 2.0 协议,允许免费商用,无需申请许可。这是 Google 开源策略的重要信号,Gemma 系列定位为对标 Meta Llama 的开源旗帜。
Q:Gemma 4 26B-A4B 和 31B 哪个值得用?
对大多数场景,26B-A4B(MoE)更值得优先考虑:推理时仅激活 3.8B 参数,速度和显存占用接近 4B 模型,但 MMLU Pro 达 82.6%、AIME 2026 达 88.3%,与 31B 差距极小(约 2-3 个百分点),而所需硬件仅需 RTX 4060。31B 的优势是架构更简单,适合需要最高精度的服务端场景。
Q:Gemma 4 支持中文吗?
支持。Gemma 4 预训练覆盖 140+ 语言,指令调优版本(-it)开箱支持 35+ 语言,中文包含在内。Q:Gemma 4 E 系列和普通版的区别是什么?
E2B 和 E4B 是专为边缘设备优化的版本,采用 Per-Layer Embeddings 技术最大化参数效率,并且是系列中唯一支持音频输入的模型。代价是上下文长度为 128K(普通版为 256K),且不支持图像以外的高分辨率视觉任务。
Q:和其他开源模型比,Gemma 4 有什么优势?
Gemma 4 的差异化在于:① Google DeepMind 的训练基础设施加持,数学和推理表现突出;② Apache 2.0 无限制商用;③ 全系列支持多模态,尤其 E 系列的音视频能力在同规模模型中罕见;④ 官方针对移动端(LiteRT-LM)和 Raspberry Pi 提供了优化支持,真正覆盖边缘 AI 场景。
小结
Gemma 4 是 Google DeepMind 迄今最强开源模型系列,于 2026 年 4 月 2 日发布,四款模型覆盖手机到服务器全场景,Apache 2.0 协议免费商用。核心亮点是:MoE 架构让 26B-A4B 以消费级 GPU 跑出接近 31B 的效果;边缘版 E2B/E4B 原生支持音频,将 AI Agent 能力下探到手机和 IoT 设备。
根据 Hugging Face 发布五天内的下载数据,gemma-4-31B-it 已累计 67.9 万次下载,gemma-4-E4B-it 达 32.1 万次,是近期开源模型发布中下载增速最快的系列之一。
本文内容基于 2026 年 4 月 Hugging Face 模型页及 Google 官方博客数据,建议参考 ai.google.dev/gemma 获取最新文档。
延伸资源
● Gemma 4 官方模型页:Hugging Face 模型卡,含完整代码示例
● Google DeepMind Gemma 主页:官方发布公告
● Ollama Gemma 4 库:一行命令本地运行
● 七牛云 AI API:兼容 OpenAI 接口格式,支持主流开源模型推理,开发者可通过统一 API Key 在同一套代码中切换 Gemma 4、DeepSeek、Claude 等模型,查看模型广场
