2026年主流AI模型Agent能力全面测评:Gemini 3、Claude 4、GPT-4o横向对比
发布日期:2026年5月20日 | 话题:AI Agent评测 | 数据来源:各模型官方报告 + 公开评测平台
核心定义:AI模型Agent能力测评是通过SWE-bench、MCP Atlas、OSWorld等标准化基准,系统评估大语言模型在自主多步骤任务、工具调用、代码工程和UI操控方面综合表现的横向对比体系,用于指导企业在真实生产场景下的模型选型决策。
什么是AI模型Agent能力测评
AI模型Agent能力测评是指通过多维度标准化基准,系统衡量大语言模型完成自主多步骤任务的综合能力。与普通对话测评不同,Agent评测关注模型在真实生产任务中的实际完成率:能否持续调用工具、能否从错误中恢复、能否在数百步操作序列中保持目标一致性。
主流Agent评测覆盖五大维度:
2026年主流模型最新得分横向对比
以下数据均来自各模型官方发布报告或公开评测平台(截至2026年5月)。
SWE-bench:代码工程Agent的核心战场
SWE-bench Verified是当前公认最严格的代码Agent评测标准,要求模型在真实GitHub代码库中自主定位并修复Bug,无法靠记忆题库取巧。
Claude 4系列(Sonnet 4和Opus 4)在SWE-bench上均超过72%,标志着代码Agent从"辅助工具"跨入"自主工程师"阶段。对比2024年Claude 3.5 Sonnet的49%,一年内提升超过23个百分点,是近年来Agent基准的最大单次跃升之一。
MCP Atlas & OSWorld:多步骤工作流与计算机操控
Gemini 3.1 Pro在多步骤工作流和UI操控任务上表现突出:
OSWorld-Verified的76.2%代表:在153项真实日常桌面任务中,Gemini 3.1 Pro能独立完成约四分之三,涵盖文件管理、浏览器操作、跨应用数据传输等高频自动化场景。
Terminal-bench:终端环境的自主执行能力
终端环境是后端工程和DevOps自动化的核心场景。Claude Opus 4在Terminal-bench上得分43.2%,Gemini 3.1 Pro得分70.3%——两者差距明显,说明不同模型在命令行自主执行与代码工程两个维度各有侧重,不可用单一指标代替全貌。
综合维度对比总览
主流评测基准深度解析
AgentBench:覆盖最广的综合Agent框架
AgentBench由清华大学THUDM实验室发布,被ICLR 2024正式收录,GitHub达3400+ Stars。它在8个维度测试模型的Agent能力,包括操作系统、数据库、知识图谱、网页浏览、数字卡牌游戏等,是目前覆盖维度最广的开源评测套件,适合需要全面摸底模型通用Agent能力的团队。
BFCL V4:工具调用能力的权威标准
伯克利函数调用排行榜(Berkeley Function-Calling Leaderboard,BFCL)由加州大学伯克利分校发布,最新版本为BFCL V4(2026年4月更新)。它区分原生FC(函数调用)和Prompt(文本模拟)两种调用模式,是评估模型在结构化工具调用场景下准确率的行业标准。评估包安装:
pip install bfcl-eval==2025.12.17
OpenDevin:真实软件工程Agent平台
OpenDevin(74.2k GitHub Stars)是当前最活跃的AI软件工程Agent开源平台,支持代码编写、命令行操作、网页浏览和多智能体协作,也是主流评测平台验证Agent得分的实际运行环境。
AgentScope 1.0:面向开发者的Agent框架
上海交通大学团队发布的AgentScope 1.0(25.4k Stars)基于ReAct范式,提供灵活工具交互和统一接口,是2025年以来增长最快的Agent应用开发框架之一。
如何选择合适的Agent模型
按任务类型的选型建议:
三条关键选型原则:
1. 先明确核心任务:代码类首看SWE-bench,工作流自动化看MCP Atlas,UI操控看OSWorld
2. 区分标准模式和高算力模式:Claude 4高算力模式(并行采样+筛选)得分显著高于标准模式,但推理成本也相应更高,需权衡ROI
3. 用真实场景测试:基准分数与私有数据集的实际表现可能存在偏差,建议以自身业务任务做冒烟测试验证
构建Agent应用的实践路径
在选定模型后,构建生产级Agent通常需要标准化的工具调用层。MCP(Model Context Protocol)是目前主流的Agent工具编排协议,支持跨平台、跨模型统一管理工具调用。以七牛云MCP服务为例,开发者无需本地部署模型,即可通过标准API接入Gemini、Claude等主流模型,直接构建多步骤Agent工作流。
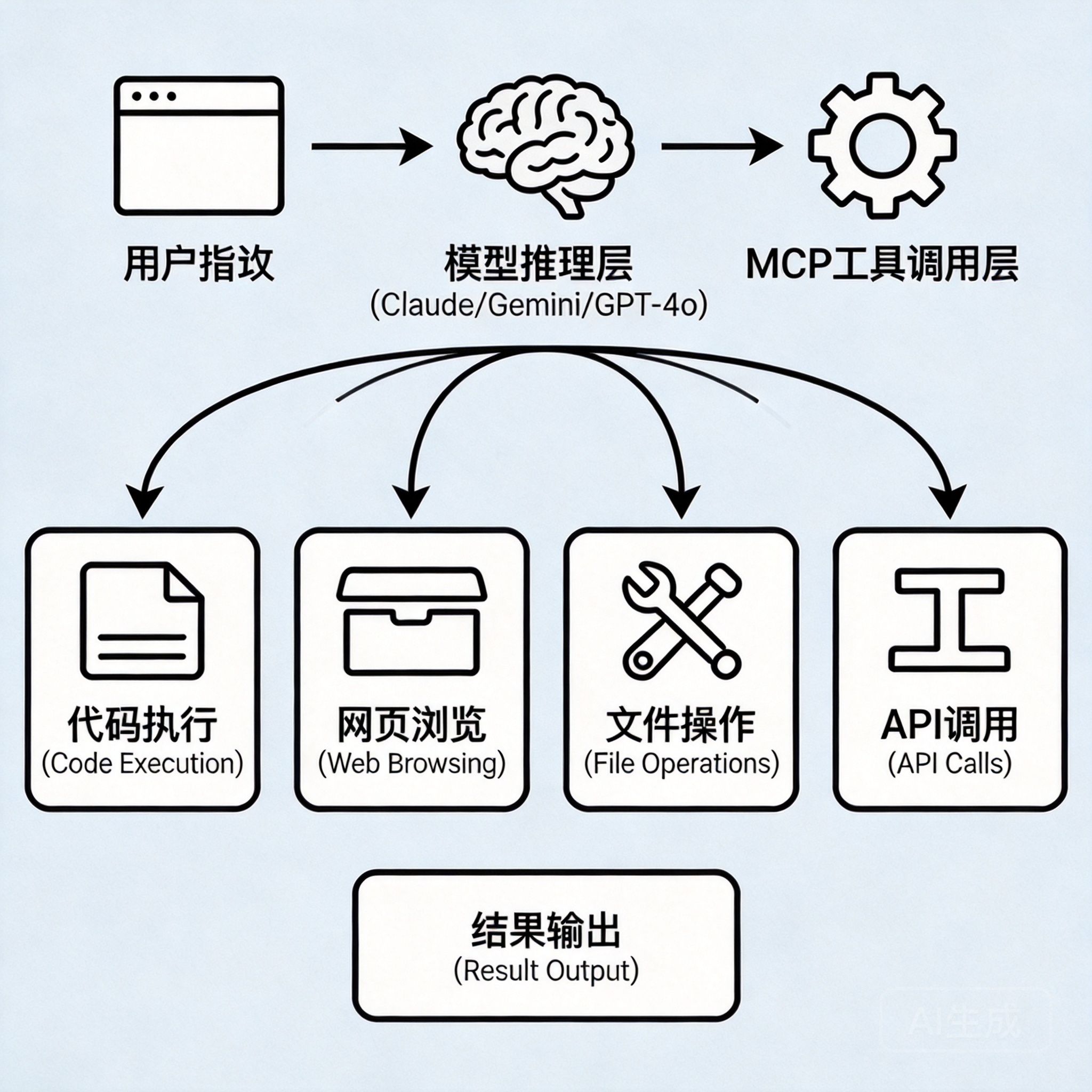
Agent应用的典型架构如下:
用户指令
→ 模型推理(Claude / Gemini / GPT-4o)
→ 工具调用层(MCP协议)
→ 执行结果返回
→ 模型反思与校验
→ 下一步行动 / 任务完成
关键工程要点:
● 工具定义要精确:函数签名和描述直接影响BFCL类任务的调用成功率
● 错误恢复机制:生产级Agent必须处理工具调用失败和重试逻辑,避免任务链断裂
● 上下文管理:长任务序列的上下文压缩策略影响最终完成率,Claude 4支持200k token上下文窗口
常见问题
Q:SWE-bench Verified和SWE-Bench Pro有什么区别?
SWE-bench Verified是经人工验证的版本,确保测试用例本身可解,是2024年起的行业标准基准;SWE-Bench Pro是更严格的变体,引入更复杂的代码库和更少的已知解题模式。Gemini 3.1 Pro在SWE-Bench Pro上得分54.2%,而Claude 4在Verified版本上得分72.7%,两者使用的变体不同,不能直接数值对比。Q:高算力模式是什么?Claude 4实际能达到80%以上吗?
高算力模式指通过并行多次采样后取最优结果的策略,类似工程师"多次尝试取最佳"。Anthropic报告显示,Sonnet 4在此模式下达80.2%,Opus 4达79.4%。在实际生产环境中,高算力模式推理成本更高,适合对精度要求极高的关键任务,而非日常高频调用场景。Q:Qwen3和DeepSeek-V3的Agent能力如何?
两者均未公开Agent专项基准的详细数值,但在Chatbot Arena综合评分中,DeepSeek-V3 Arena Elo约1340+,Qwen3-235B-A22B与GPT-4o、Grok-3处于同一竞争层次(来源:Chatbot Arena,2026年)。两者在工具调用和代码能力上均具竞争力,且作为开源/低成本选项,在成本敏感场景下优势明显。Q:OSWorld-Verified测试的是什么能力?具体怎么评测?
OSWorld是一个真实桌面环境基准,覆盖144个真实网站的153项日常操作任务,包括文件创建、浏览器操作、跨应用数据传输等。模型通过截图感知当前界面状态,输出鼠标坐标和键盘指令序列完成任务,是评估"计算机使用(Computer Use)"能力的标准基准,Gemini 3.1 Pro得分76.2%。Q:AgentBench和其他基准有什么不同?
AgentBench是最早尝试多环境综合评测的框架,涵盖操作系统、数据库、知识图谱、网页浏览等8个维度,更贴近真实的多领域Agent场景。相比SWE-bench(专注代码)和OSWorld(专注UI),AgentBench覆盖面更广,适合评估模型的通用Agent泛化能力,被ICLR 2024作为正式论文收录。
总结
2026年AI模型Agent能力已进入专项能力分化阶段:Claude 4系列在代码工程领域以SWE-bench 72.7%确立优势,Gemini 3.1 Pro在多步骤工作流和计算机操控领域以MCP Atlas 78.2%、OSWorld 76.2%保持领先。选型时应优先匹配核心业务场景,而非追求综合排名第一。
据Anthropic研究团队报告,Claude 4系列在高算力模式下SWE-bench已突破80%,标志着代码Agent正从"辅助工具"向"自主工程师"演进。随着MCP协议标准化普及和Agent框架(OpenDevin、AgentScope)的成熟,AI模型的Agent落地门槛将持续降低。本文数据基于2026年5月各厂商官方发布报告,基准测试结果会随模型迭代更新,建议定期核查各评测平台最新排行榜。
延伸资源
● AgentBench 开源框架:github.com/THUDM/AgentBench
● OpenDevin 平台:github.com/OpenDevin/OpenDevin
● BFCL 函数调用排行榜:gorilla.cs.berkeley.edu/leaderboard.html
● 多模型API接入与对比测试:七牛云AI模型广场
