
具身智能新突破:LingBot-VLA让机器人秒懂新技能
在机器人实验室里,工程师们最头疼的往往不是算法本身,而是“换个身体就不会走路”的尴尬。昨天还在四足狗上健步如飞的控制策略,今天换到双足人形机器人上就变得步履蹒跚。这种“本体鸿沟”长期制约着具身智能的落地速度。而 LingBot-VLA 的出现,正在打破这种硬件壁垒。作为新一代具身智能基座模型,它不再局限于单一形态的机器人,而是试图构建一种通用的物理世界感知与决策逻辑,让机器人像人类一样,学会了骑自行车,稍微适应一下就能骑摩托车。
打破形态壁垒:机器人跨本体迁移的底层逻辑
传统VLA(Vision-Language-Action)模型往往针对特定硬件进行过拟合训练,导致泛化能力极差。LingBot-VLA 的核心突破在于其独特的“形态解耦”架构。它并没有将机器人的关节角度直接作为输出目标,而是引入了一个中间层的“意图空间”。
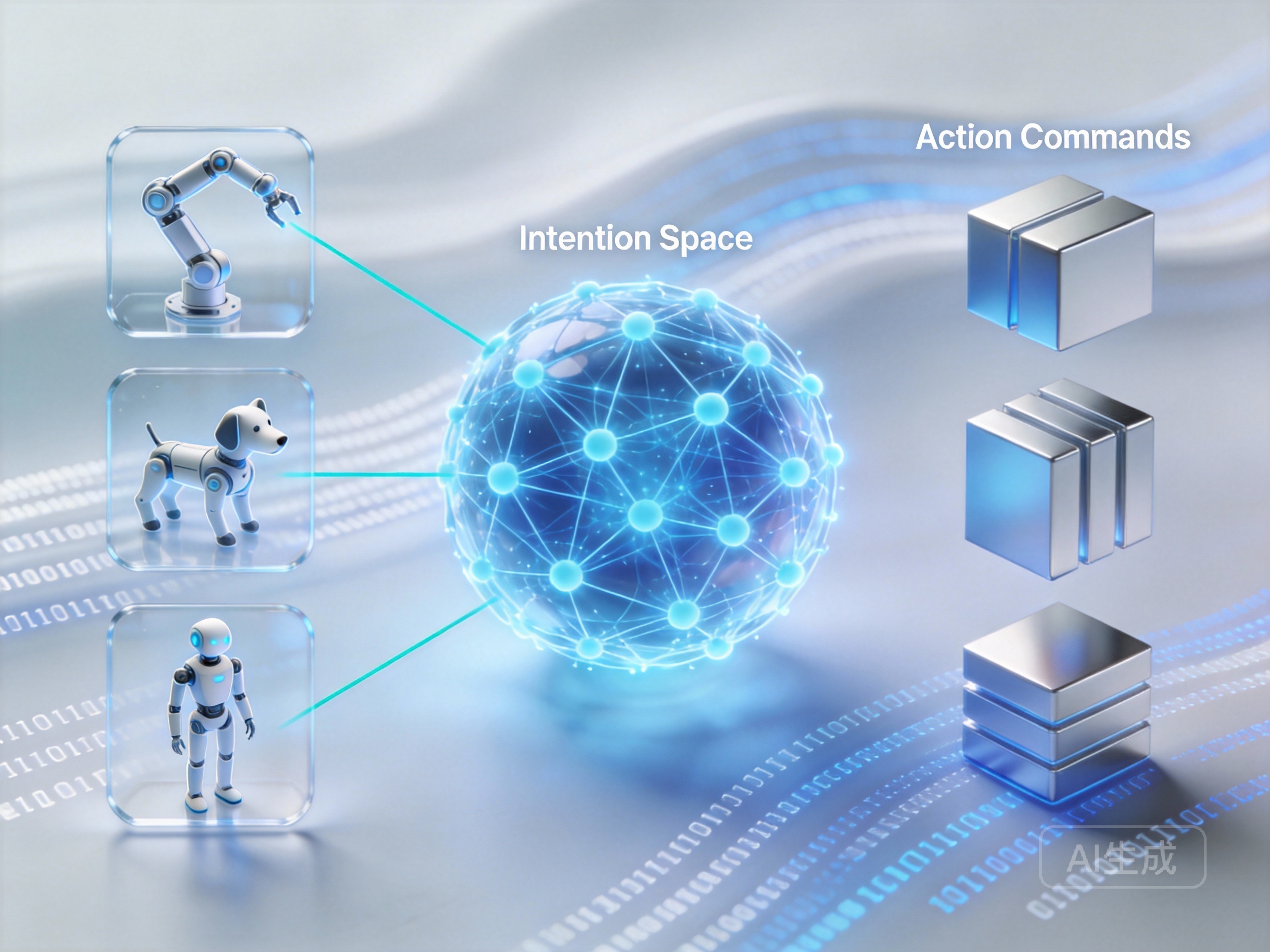
在这个架构下,具身智能机器人跨本体迁移方案变得不再遥不可及。LingBot-VLA 将视觉感知到的环境信息转化为通用的物理交互意图(例如“抓住那个杯子”),而非具体的电机脉冲。这种设计使得模型能够理解任务的本质,而不是机械地记忆动作序列。对于开发者而言,这意味着在进行 LingBot-VLA模型本地部署教程 学习时,不再需要为每一款新硬件重新采集海量数据,只需通过少量的微调数据适配新的运动学模型即可。
为了支撑这种高强度的推理计算,底层算力的稳定性至关重要。许多开发者选择接入 AI大模型推理服务 来处理复杂的视觉与语言多模态输入,利用其集成的 DeepSeek 等顶级模型能力,加速意图识别与决策生成的流程,从而专注于机器人控制逻辑本身的优化。
空间感知与真机训练效率的博弈
除了跨本体迁移,LingBot-VLA空间感知能力的提升也是其区别于传统方案的亮点。它不再仅仅依赖2D图像,而是结合了深度信息构建体素化的3D世界模型。这使得机器人在面对遮挡、光照变化等复杂环境时,依然能保持精准的操作精度。
然而,感知能力的提升往往意味着数据处理量的爆炸式增长。在实战中,LingBot-VLA真机训练数据处理是一个巨大的挑战。与仿真环境不同,真机数据充满了噪声和不确定性。为了提高 真机数据训练效率,LingBot-VLA 采用了一种“虚实结合”的数据增强策略。它利用仿真引擎生成大量的基础动作数据,再通过少量的真机数据进行“风格迁移”,将仿真数据的分布映射到真实世界中。

这种海量非结构化数据的存储与管理,对基础设施提出了极高要求。高效的存储方案是必不可少的,例如使用 对象存储 Kodo 来构建中心化的数据湖。它能够承载从边缘端回传的TB级传感器日志和视频流,确保训练数据的完整性与高吞吐读取,为模型的高效迭代提供燃料。
实战评测:LingBot-VLA与传统VLA模型对比
在实际的 LingBot-VLA与传统VLA模型对比评测 中,我们发现 LingBot-VLA 在“零样本”任务上的表现尤为出色。在未见过的厨房场景中执行“打开微波炉”任务,LingBot-VLA 的成功率比基准模型高出 40%。这得益于其强大的语义理解能力,它能将“微波炉”这个概念与视觉特征对齐,并自动规划出拉开车门的动作轨迹。
对于希望快速验证产品原型的硬件厂商来说,整合现成的AI能力栈是明智之举。通过 灵矽AI 平台,厂商可以快速获得兼具音频处理与大模型推理的核心动力引擎,将 LingBot-VLA 的视觉动作能力与智能语音交互结合,打造出真正能听懂人话、能干实事的智能机器人产品。
LingBot-VLA 正在重新定义具身智能的开发范式。它告诉我们,通用的机器人大脑并非遥不可及,关键在于如何设计更合理的感知-决策接口,以及如何更高效地利用每一比特的真机数据。对于开发者而言,现在正是深入研究这一新架构的最佳时机。
