
豆包模型调用爆发:企业智能体Token经济与算力成本优化实战
近期,许多研发团队在核对云端账单时,发现了一项激增的开支:大模型API请求费用。这不是偶然波动,而是由业务流深度接入AI所引发的必然现象。尤其是表现优异的国产模型被广泛集成后,调用量爆发让不少企业措手不及。
这种现象标志着IT基础设施计费逻辑的根本转变。我们正在进入一个以Token经济商业模式为核心的新阶段。在这个模式下,每一段上下文、每一次工具调用,都直接与算力成本挂钩。传统的服务器包年包月计费,正逐渐让位于按Token计费的精细化运营。面对这种转变,如何平衡高频交互与高昂成本,成为了技术团队必须跨越的门槛。
业务流重塑与调用量激增的底层逻辑
当前,单一的对话框早已无法满足复杂的业务需求。企业开始构建具备规划、记忆和执行能力的复杂系统。这些系统在后台默默处理着海量数据,每一次状态流转都需要与大模型进行多次交互。
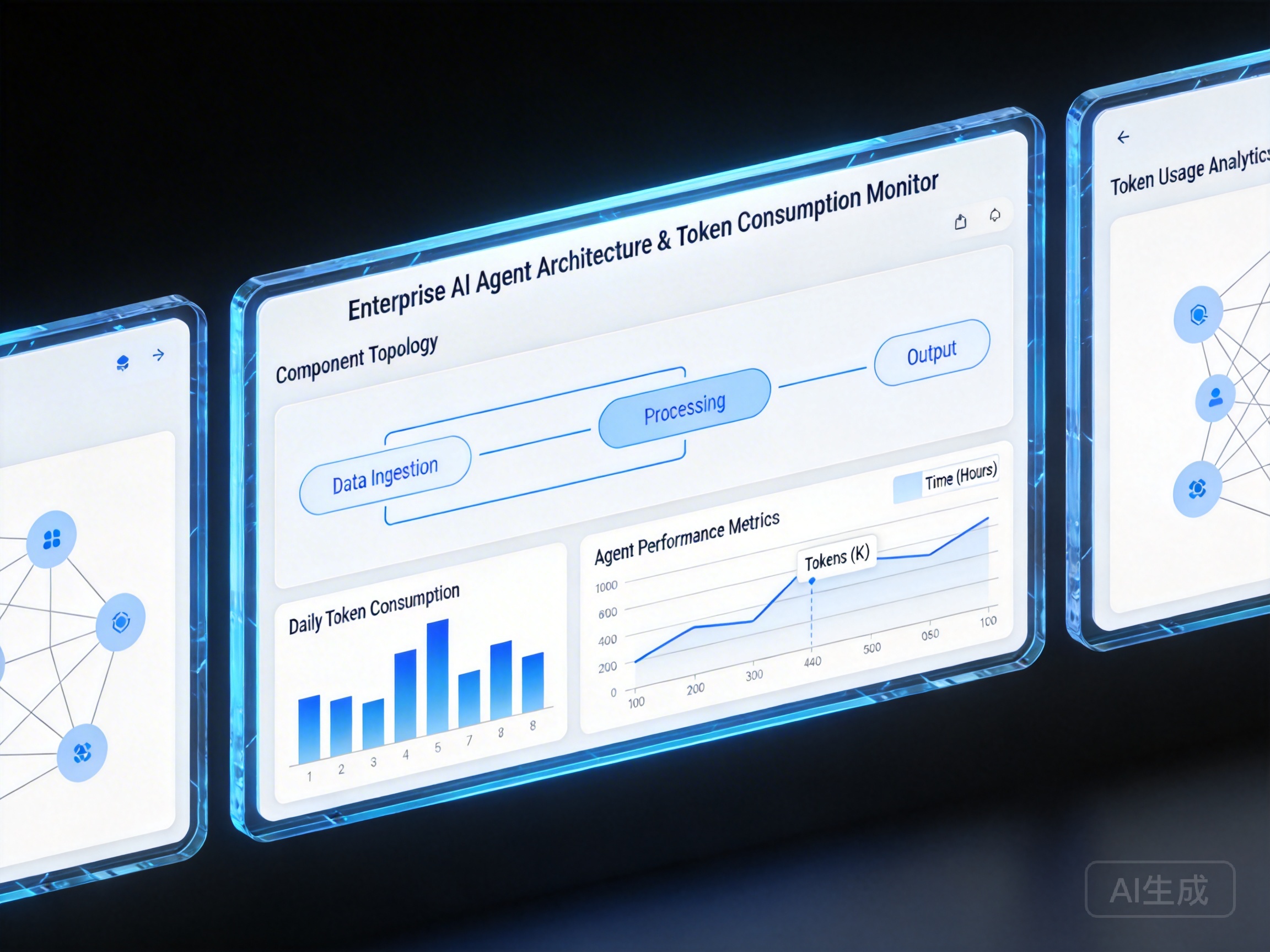
当这种架构被部署到实际生产环境中,豆包大模型API调用量爆发应对方案就成了技术架构师的案头必备。因为一个看似简单的用户指令,可能会在后台触发数十次的模型反思与工具查询。如果不加以限制和优化,这种指数级的Token消耗将直接击穿项目的利润模型。
为了规范这种复杂的交互,开发者需要标准化的编排工具。通过引入企业级智能体的MCP接入服务,团队可以实现多工具服务的云端安全聚合与统一管理。这种标准化的模型能力编排,不仅让开发者无需本地部署即可快速构建具备复杂工具调用能力的Agent应用,还能在架构层面为后续的Token治理打下基础。
算力成本优化与Token精细化管理
面对激增的账单,粗暴地限制用户请求显然是不明智的。我们需要从工程实现的角度寻找大模型推理算力成本优化的路径。
核心策略在于减少无效上下文的传递。针对如何优化企业级智能体Token消耗成本这个问题,最直接的做法是引入语义缓存机制(Semantic Cache)。当系统接收到相似的查询时,直接从缓存中返回结果,从而彻底绕过大模型的推理环节。此外,对Prompt进行结构化压缩,剔除冗余的指令描述,也能在单次请求中节省可观的Token。
在选择接入平台时,灵活性和性价比同样重要。对于需要高频交互的场景,豆包大模型API调用通过统一的API Key管理服务,提供了完美兼容OpenAI与Anthropic标准的接入端点。开发者可以一键创建密钥,并利用其覆盖的实时推理、图文生成等全栈AI能力,实现低门槛的高效集成。
拥抱新时代的算力基建
仅仅依靠代码层面的优化是不够的,底层推理平台的选择往往能带来事半功倍的效果。一份完整的Token经济商业模式下的AI算力优化教程,必然会强调多模型路由与平台级调优的重要性。
通过接入像七牛云AI推理这样的全开放平台,企业可以获得集成顶级大模型的统一入口。它不仅完美兼容双API标准,还支持联网搜索与深度思考,为开发者提供了高性能、低门槛的一站式大模型接入方案。这种平台级的支持,能够帮助企业在享受最新模型能力的同时,将推理成本控制在合理范围内。
Token经济并不是技术的阻碍,而是促使工程实践走向精细化的催化剂。通过合理的架构设计、精准的缓存策略以及高效的推理平台,企业完全可以在控制成本的前提下,释放AI的最大潜能。未来的技术壁垒,将建立在对每一个Token的极致利用之上。
