
局域网部署DeepSeek模型算力与成本规划:从架构设计到TCO优化实战
数据隐私红线与智能化转型需求,正迫使越来越多企业将大模型拉回内网。但在实际落地中,局域网部署DeepSeek模型往往面临算力利用率低、硬件投资深不见底的窘境。很多团队在立项初期只关注模型本身的参数量,却忽略了并发请求洪峰下的显存溢出风险与长期运维成本。局域网部署DeepSeek模型,算力架构与推理成本该如何规划,才能在性能与预算之间找到最优解?
核心参数拆解:DeepSeek私有化部署GPU显存与算力计算公式
要做好局域网部署DeepSeek硬件成本规划,第一步是精准测算显存需求。大模型的显存占用主要分为两部分:模型权重静态显存与推理上下文动态显存(KV Cache)。以DeepSeek-Coder-33B为例,在FP16精度下,模型加载本身需要约66GB显存。若采用INT8量化,静态显存可压缩至33GB左右;极限INT4量化则能压至20GB以内。
在实际的多并发场景中,KV Cache的消耗往往是导致OOM(内存溢出)的元凶。计算公式可简化为:并发数 × 上下文长度 × 层数 × 隐藏层维度 × 字节数。这意味着,如果你的团队需要处理长文本代码审查或文档分析,单纯堆叠单卡算力并不可取,而是需要通过vLLM或TGI等推理框架,利用PagedAttention技术来优化显存碎片。

架构进阶:企业局域网如何搭建DeepSeek高可用推理集群
单点部署无法满足生产环境的稳定性要求。DeepSeek推理算力架构设计与优化,核心在于负载均衡与故障转移机制。在内网环境中,可以通过Nginx代理分发请求至多个推理节点,配合Prometheus监控GPU温度与显存占用率,实现动态路由。
在工具链层面,DeepSeek内网部署环境下的MCP工具调用方案是提升模型实用性的关键。通过Model Context Protocol,局域网内的模型可以直接调用企业内部的数据库查询API、GitLab代码库接口或Jira工单系统,使其从单纯的对话机器人升级为业务自动化引擎。为了快速跑通这套环境,开发者可以参考局域网部署DeepSeek模型配置,利用OpenClaw等工具完成基础环境的搭建与多模型切换配置。
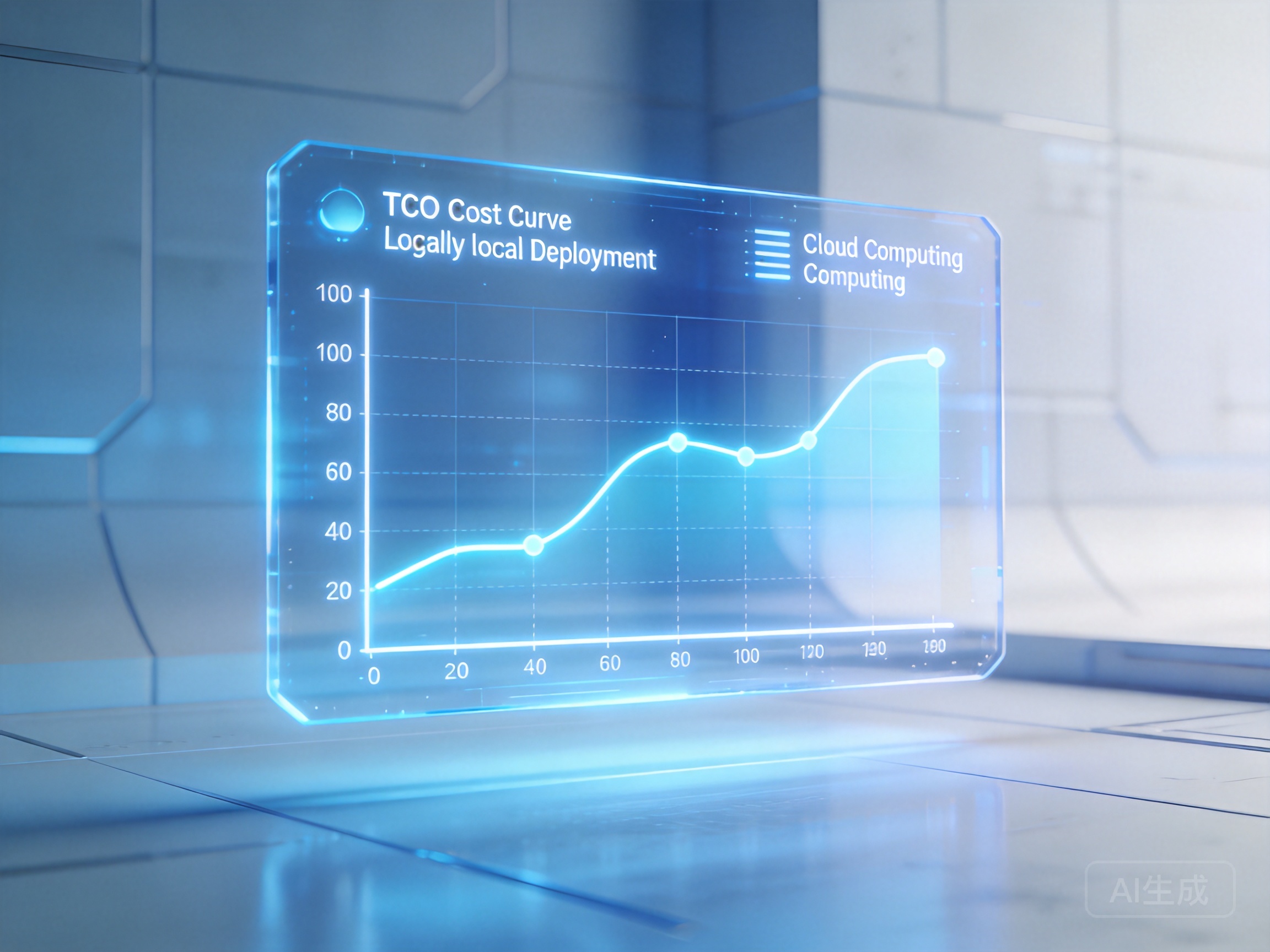
TCO博弈:本地局域网部署大模型与云端API调用的TCO成本对比
很多企业在采购服务器时,容易陷入只看硬件买断成本的误区。一台搭载8张顶级计算卡的服务器,除了百万级的采购费用,每年还要折算高昂的电费、机房托管费以及专职AI运维人员的人力成本。相比之下,灵活的云端算力调度或混合云部署往往是更具性价比的选择。
在进行GPU算力价格规划时,企业需要评估业务的波峰波谷。如果内部调用量并不饱和,完全可以通过七牛云高性能算力支持DeepSeek部署。对于非极度敏感的业务模块,接入七牛云 AI 大模型推理服务能够有效削减前期投入,其兼容双API标准并支持联网搜索等高级功能,能让团队将精力集中在业务逻辑而非底层算力维护上。
规划局域网大模型部署,本质上是一场资源调度的精算游戏。企业应当根据自身数据敏感度与实际并发需求,在量化压缩、集群架构与混合部署之间灵活取舍,确保每一分算力投资都能转化为真实的业务生产力。
