
突破性能瓶颈:LangChain Agent开源框架私有化部署与推理全链路优化指南
很多企业在尝试将大模型能力引入业务流时,往往卡在数据隐私合规这一关。将模型搬回本地机房看似安全,但随之而来的却是让人崩溃的响应延迟和环境配置地狱。要真正让智能体在企业内部跑得快、跑稳,一套完整的 LangChain Agent开源框架私有化部署:从底层环境配置到推理链路优化 方案必不可少。这不仅仅是把代码拉取下来运行那么简单,而是涉及从显存分配、并发处理到工具链协议对接的系统性工程。
摆脱配置泥沼:企业级 LLM 应用本地化环境配置
许多开发者在初期都会抱怨本地化部署的 Agent 反应迟钝。探讨 LangChain Agent本地化部署如何提升推理速度,核心必须聚焦于底层推理引擎的选型与显存管理。传统的 HuggingFace Pipeline 虽然易用,但在多并发请求场景下极易发生显存溢出。
针对企业级 LLM 应用本地化环境配置,建议直接采用 vLLM 或 TensorRT-LLM 作为底层推理后端。这些框架利用 PagedAttention 技术动态管理显存,能够将吞吐量提升数倍。在底层环境搭建时,需严格对齐 CUDA 版本与 PyTorch 依赖,避免因算子不兼容导致的隐性降速。

接口标准化:兼容OpenAI接口的Agent全链路优化教程
完成了底层环境的搭建后,大模型 Agent 推理全链路优化 的关键一步是接口的标准化转换。为了降低业务代码的迁移成本,强烈建议在私有化模型前封装一层兼容 OpenAI API 格式的网关。这样一来,上层的 LangChain 逻辑几乎无需修改即可无缝对接本地模型。
如果在业务高峰期本地算力遇到瓶颈,这种标准化的接口设计也方便企业采用混合云架构。此时可以快速接入 七牛云AI推理 这样的全开放平台,它完美兼容 OpenAI 和 Anthropic 双 API,能作为本地算力的有效补充,确保业务高可用。对于想要深入了解如何基于标准接口从零构建智能体的开发者,建议参考这份详实的 Agent 实战指南,其中拆解了从基础调用到复杂逻辑编排的完整代码实现。
工具链升级:开源大模型MCP协议私有化接入实战方案
智能体的核心价值在于灵活调用外部工具。传统的硬编码工具调用方式不仅扩展性差,还容易引发安全漏洞。引入 MCP(Model Context Protocol)协议是目前解决这一痛点的最佳实践。
通过一套标准的 开源大模型MCP协议私有化接入实战方案,我们可以将本地数据库查询、企业内部 ERP 接口统一封装为标准化工具提供给大模型。在具体实施时,开发者可以查阅 MCP服务使用说明文档,了解如何实现多工具服务的云端或本地安全聚合,免去繁琐的鉴权与网络打通工作。
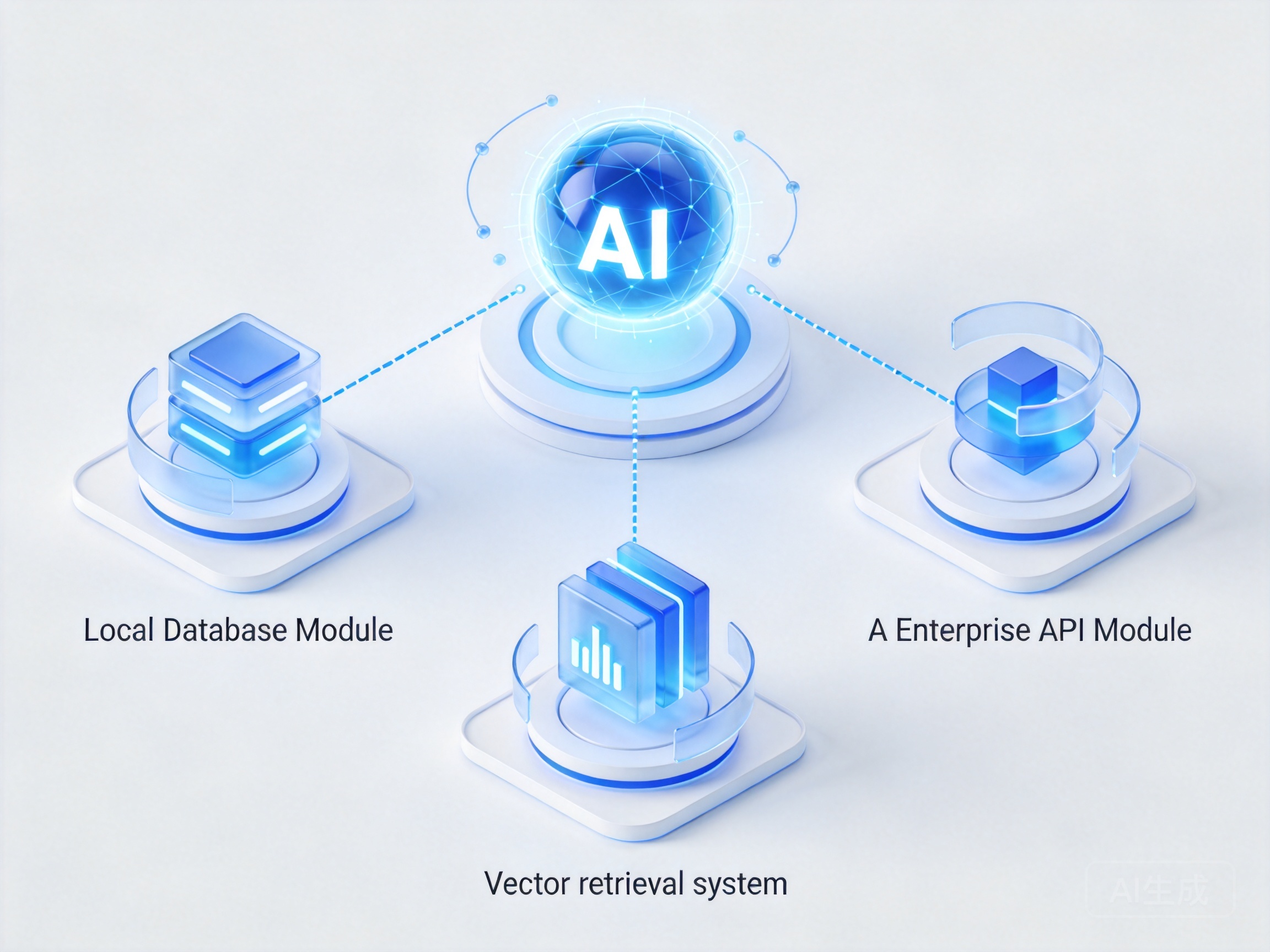
将 MCP 协议与 LangChain 检索增强生成 (RAG) 实战 深度结合,能够极大提升 Agent 处理复杂专业业务的能力。例如,在处理长文本合同审查时,Agent 可以先通过 MCP 调取本地向量数据库的检索工具,精准获取相关条款上下文,再交由大模型进行逻辑推理与风险提示,从而有效规避大模型常见的幻觉问题。
私有化部署智能体是一场深度的系统级调优战役。从底层算力压榨到上层协议规范,每一个环节的打磨都能为最终的业务体验带来实质性跃升。团队在上线初期应建立完善的 Token 消耗与推理延迟监控大盘,根据实际并发流量动态调整 GPU 资源池,让企业级大模型应用真正发挥出业务价值。
