
智能体搜索增强优化:API防限流与召回率提升实战避坑
构建生产环境中的AI应用时,开发者通常会遭遇两座大山:一是业务高峰期突发的高并发导致接口被无情限流,二是知识库检索出的上下文毫无关联,导致大模型频繁产生幻觉。单纯依赖基础的向量比对早已无法满足复杂的真实业务场景,进行智能体搜索增强优化:API防限流与召回率提升实战避坑,已经成为每位AI工程师必须跨越的工程化门槛。这绝不是简单地增加几层Redis缓存就能解决的问题,而是需要从底层链路重新审视系统的健壮性与检索的精确度。
大模型API防限流与高可用架构设计指南
面对海量用户请求,如何解决大模型API高并发限流问题是保障系统稳定性的核心战役。很多团队在初期直接将前端请求透传给大模型厂商的接口,一旦遇到突发流量,瞬间就会触发 HTTP 429 Too Many Requests 错误,导致整个智能体服务瘫痪。
为了打造坚如磐石的AI智能搜索系统高可用架构设计指南,我们需要在网关层引入多维度的流量管控策略。核心方案是采用令牌桶算法结合请求队列机制。当瞬间并发超过大模型厂商设定的阈值时,网关不应直接拒绝请求,而是将其放入具有超时机制的异步队列中,平滑地将流量削峰填谷。

此外,多渠道模型路由是防限流的另一大法宝。系统应具备动态回退机制,当主用模型接口响应延迟飙升或被限流时,无缝切换至备用模型。为了降低接入和管理多模型的复杂度,开发者可以直接使用 七牛云API key 统一管理端点。它不仅完美兼容主流标准协议,还支持一键创建密钥,让企业能以极低的门槛集成顶级大模型能力,有效分散单点故障风险。对于具体的接入细节与全栈AI能力调用,参考完整的 AI大模型推理服务 文档,能够帮助技术团队快速完成从密钥获取到高可用架构落地的全流程部署。
智能体知识库混合检索架构优化方案
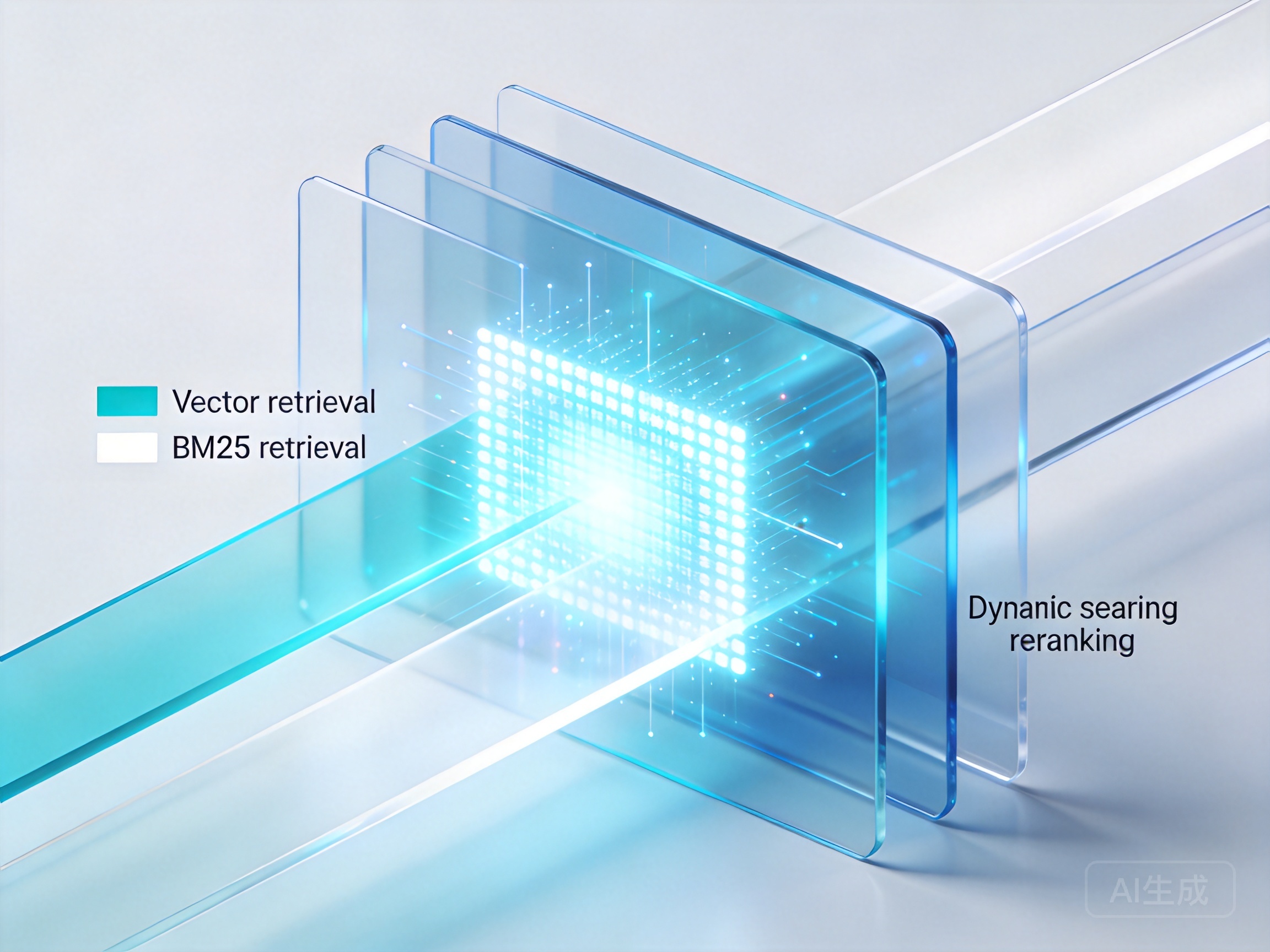
解决了请求层面的稳定性后,接下来的硬骨头是检索质量。在企业级RAG系统召回率提升实战中,单路向量检索往往在面对专有名词、缩写或特定产品型号时表现得一塌糊涂。这是因为向量检索擅长捕捉语义相似度,却对精确的字面匹配极度不敏感。
要真正落地一套优秀的智能体知识库混合检索架构优化方案,必须引入“向量检索 + BM25全文检索”的双路混合召回机制。当用户输入查询时,系统同时在向量数据库中寻找语义相近的片段,并在倒排索引中查找关键词匹配度高的文档。随后,通过重排模型(Reranker)对两路召回的结果进行交叉打分和重新排序,将最符合语境的内容推送到头部。
在这个过程中,智能体还需要具备动态调用外部工具的能力,以补充实时数据或执行复杂查询。通过查阅 MCP服务使用说明文档,开发者可以利用这种标准化的模型能力编排平台,将企业内部的数据库查询工具、API接口与智能体无缝对接。这种云端安全聚合的管理方式,使得Agent能够在检索本地知识库的同时,动态拉取外部最新数据,从而大幅度提升最终生成内容的准确性和时效性。
工程化落地的持续演进
优化智能体系统是一场没有终点的工程化演进。从网关层的流量整形到检索层的多路召回与重排,每一个环节的微调都能带来用户体验的显著跃升。技术团队应当建立完善的打点监控体系,实时追踪接口的Token消耗率、请求排队延迟以及Top-K召回的准确率。只有将防限流的坚固盾牌与高召回率的锋利长矛结合,智能体才能在复杂的商业环境中真正发挥出降本增效的核心价值。
