
WebRTC流式语音:企业级低延迟实时交互Agent端到端方案实战指南
当用户对着AI硬件或虚拟助理说话时,超过1秒的响应延迟或无法自然打断的生硬体验,足以摧毁产品建立起的信任感。传统的HTTP请求-响应模式早已无法满足高频、拟真的人机交互需求。为此,基于WebRTC流式语音的企业级低延迟实时交互Agent端到端方案成为破局关键。本文将深入拆解从底层音频传输、VAD精准打断到大模型推理与工具调用的全链路优化策略。
WebRTC实时流式语音架构设计与穿透技术
探讨如何构建低延迟WebRTC语音Agent系统,首要任务是重塑数据传输通道。传统的WebSocket虽然能实现双向通信,但在弱网环境下容易出现队头阻塞问题。WebRTC实时流式语音架构设计的核心在于利用UDP协议的无连接特性,结合RTP/RTCP协议族,消除冗余的信令交互与传输延迟。
在复杂的企业级或家庭网络环境中,WebRTC穿透技术在实时语音Agent中的应用显得尤为重要。通过部署高可用的STUN/TURN服务器集群实现NAT穿透,能够确保端到端的媒体流直连或高效转发。为了支撑海量并发并保障音视频通信的QoS(服务质量),底层网络基础设施的选择至关重要。例如,通过引入RTC超低延迟互动技术,开发者可以显著优化开播延迟、丢包重传及冗余传输机制,将端到端通信延迟压缩至毫秒级,为上层的大模型推理争取宝贵的时间窗口。
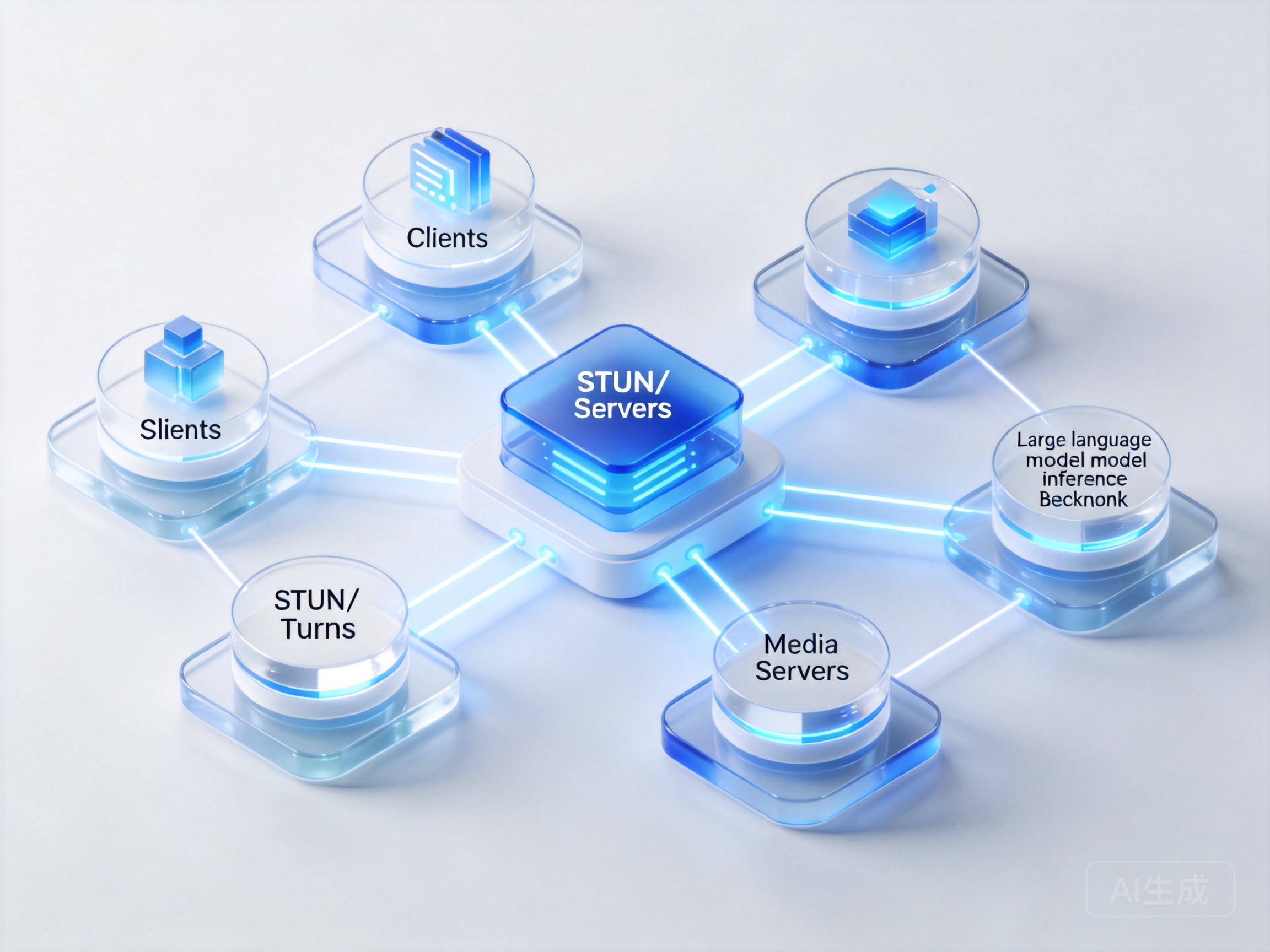
全双工流式VAD打断机制与延迟优化
要实现真正自然的人机对谈,不仅需要大模型响应速度快,还要让机器“听得懂”用户何时插话并及时闭嘴。这份大模型流式语音VAD打断延迟优化教程的核心秘诀在于:将VAD(语音活动检测)算法前置到流式音频处理的边缘端或极速节点,而非等待整句音频上传完毕。
全双工流式VAD打断机制与延迟优化要求系统在检测到有效人声的100到200毫秒内,迅速切断当前的TTS(文本转语音)播报流,并同步清空大模型的生成缓存。借助于灵矽AI语音引擎这类集成了智能知识库与音频处理的全栈核心动力引擎,开发者能有效降低端侧设备的算力压力,实现精准的人声检测、噪音抑制与毫秒级打断响应,彻底告别机器自顾自说话的尴尬场景。
企业级AI语音实时交互端到端解决方案的落地
低延迟实时音视频通信系统构建不仅仅是音视频通道的搭建,更涉及复杂的业务逻辑与外部服务编排。现代Agent智能体在交互过程中往往需要调用外部工具、查询实时天气或访问企业私有数据库,这些操作如果处理不当,会急剧增加整体链路的响应延迟。

通过标准化协议实现多工具服务的云端安全聚合是解决这一痛点的有效途径。利用MCP服务Agent构建能力,开发者可以无需繁琐的本地部署,快速接入多模型生态与工具链。这种云端托管与编排机制让Agent在保持超低延迟语音交互的同时,具备了强大的复杂任务处理能力,真正完成了从单一对话机器人到全能数字员工的进化。
构建真正可用的语音Agent,是一场与毫秒级延迟较量的系统工程。从WebRTC底层通道的打通,到流式VAD的精准打断,再到云端模型与工具链的无缝编排,每一个节点的细微优化都决定了最终的交互体验。开发者应当摒弃拼凑式的技术栈,转向一体化、标准化的端到端架构,从而打造出真正具备沉浸感的AI交互产品。
