微服务系统有哪些治理要点?高并发系统稳定性如何保障?
微服务系统治理要点
流量管理
首先从微服务系统来讲,很多时候治理是从流量角度来看的。比如我们从前面客户侧开始,把流量一步一步规划到后面的微服务系统上去,做一个流量的梳理。

整个流量链路上,有一些比较常见的方案。今天重点和大家分享流量管理的内容。我们在做服务的时候,经常会发版本。因为对微服务来讲,我们的微服务本来就是为了系统快速去迭代,每一个团队做一个比较小的系统。我们之前把生产的集群分为很多个——预发的、灰度的、正式的林林总总。我们做灰度发布就是让我们的每一个功能上线时,是一个循序渐进往前推进的过程,而不是一下子把所有问题暴露给所有用户。这样当灰度发布的过程中遇到问题,就可以停止发布,修改到没有问题再继续进行了。
灰度发布也有很多实现方案。首先可以用内部预发的方式。比如说一个公司几百号人,先让内部的人使用这个新版本。再比如说在发版的时候,选择合适的时间发布窗口,发布以后定义下一个窗口,如果没有人为干预,那我从灰度集群上就往正式集群上去滚动去更新。比如说我先滚进一个正式集群,没有问题就继续进行,如果有问题,它整个系统就会停止进而等待人为干预,如果没有问题的话,就会自动把整个流程进行规范。
另外,我们还可以从 Nginx 来控制,用权重来控制打到哪个上面去,这样就是比较随机地来做分发。我们可以看图,现在对于云原生来讲这是一个比较典型的场景,相对来讲比较大的公司可能会选这种控制面的方式来做处理。这是灰度发布这个阶段的逻辑。
其实做产品最难的是做决定,流量管理中我们可以采用 A/B test 的方式。业务侧决定不是很有把握的时候,我们就需要提供这样一个平台,帮助我们的产品。如图所示,比如两个正交的功能上可以切分流量,在上面一层我会切成这个功能打开或者是关闭,下面一层另外一个功能打开或者是关闭,把流量导到后面去。只要是两个正交功能的拆分,其实就可以并行地去做 A/B test。这种方式对我们来讲,我觉得也是属于流量管理相关的范畴,对业务的帮助也比较多。
服务发现
第二我们来看治理方面。对微服务而言,流量是从前往后的,比如 API gateway 要往后去调。对我们的架构选择来讲,其实它是有这种传统的,就是非云原生的方式。

比如对一个刚起步的公司来讲,我的服务发现在同一个机器上面,这个时候你的服务发现就相对比较容易,把端口 localhost 直接写在里面,就是直连的方式。如果你在多个 ECS 上面去跑,也可以通过 ETCD、consoul、nacos 等等一系列的方式来去做服务发现。所以你可以看到,这种传统的方式其实比较直白。
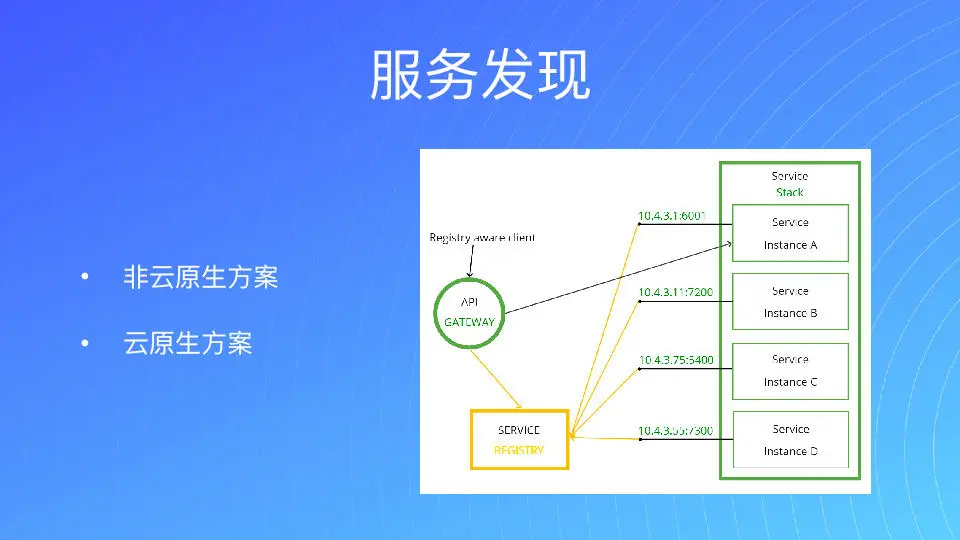
除此之外还有云原生的方式,其实对我们现在来讲,云原生的方式就相对来就比较容易,在 Kubernetes 里面就有一个虚拟的 service,你去访问这个 service 就好了。但我们怎么去处理服务发现呢?其实说白了,就是有一个服务注册的中心,那我们后面的每一个服务都会上报到服务注册中心去。我要用的时候就可以直接去调用它,这是比较传统的方式。

那么对于云原生的方式而言,其实 Kubernetes 也是通过 etcd 的方式来实现的,它只是把后面的服务提炼成一个虚拟的 service,就相当于就用一个 endpoint 来描述了。就是我所谓每一个 pod 都会注册到我的 endpoint 里面去。我在调用方只要去 watch 这边 endpoints 的对象,就可以知道有哪些 pod 注册在上面。对于我们来讲,就可以通过它来完成我们的服务发现。
通过我们在社区的交流,endless 也是比较常用的方式。比如说 DNS 就是一个大的服务发现中心,我们每访问一个域名,它都要先到 DNS 服务器去拿对应的 IP,然后才会把请求发到这个 IP,只是把 host 带上,所以它也是一个 DNS 的发现。对于 Kubernetes 还有一种方式就是 helicopter,比如我们直接用一个 service 去调,那你调 GRP 的时候,它会拿到一个 IP,但是对于 GRP 的标准来讲,它是一个长链接,拿了以后不会追加到其他上面去。所以说我们必须要用 helicopter 这种方式。相当于拿 DNS 记录时,让我自己去做选择。当然在云原生领域,还是 Kubernetes 最方便。
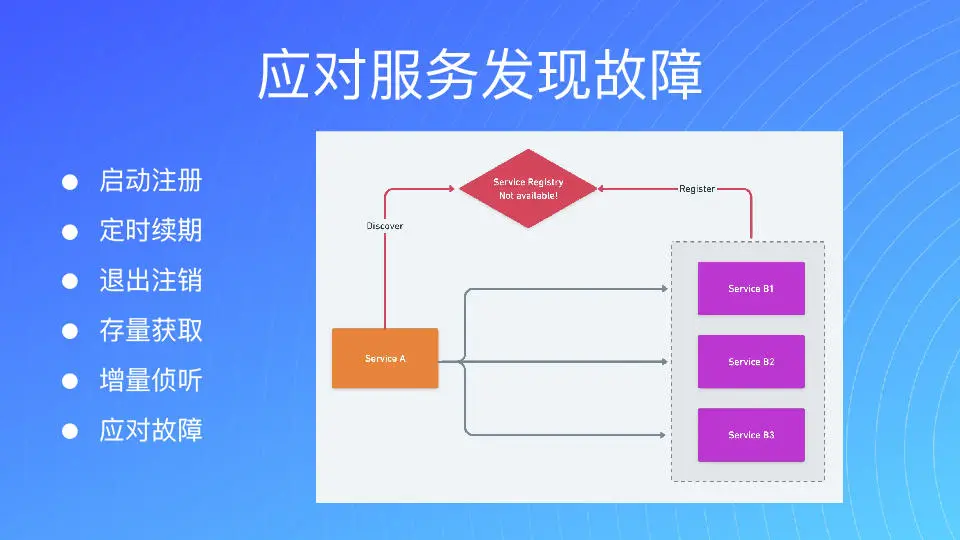
对于微服务发现来讲,我们在用的时候要尽可能应对一些服务发现的故障。我一直强调要面向故障编程,即使服务出现问题,对我们后续的服务不会产生重大影响的,这种在设计的时候我们要去考虑。
服务拆分
我们在拆分服务的时候,一定要注意治理,为保证服务质量,一定要让服务拆分得比较正交。我们也不要把服务拆得过细,这是治理非常核心的部分。我始终强调,我们在服务架构选型和治理的各方面,应该保持它足够简单。一般情况下,这种方式能够用就要保持克制,够用就可以了,有一定的前瞻性是没错,但是不要太过于超前。

然后对于服务治理来讲,还有一个点是非常重要的,就是微服务的链路比较多。从前面 API gateway,然后再调到后面的 service、DB,有的可以缓存等等。那当我们推进一个问题的时候,怎么能去快速地定位问题?如果链路跟踪没做,那么当问题出现以后,排查就很麻烦,你压根不知道在哪,只能一个环节一个环节去排除。排除最快的方案无非就是二分查找,但是如果我们能把链路跟踪做好的话,其实在日志系统里面一搜,所有链路上就全出来了,这个效率明显提升很多。
微服务可观测性
我们在设计一个系统的时候,从开始就要考虑链路的可观测性。不光是链路跟踪,和日志也息息相关。我们一般会把信息打到我们的日志里面,再通过日志采集的方式来完成。
度量系统也是属于我们流量治理的一部分,我们基于度量和错误信息,要去产生监控、去报警。因为我做过不少系统,其中的经验就是要在用户和客户发现问题之前,自己先找到问题,不要后知后觉。我们的监控报警是一定要跟上的。

所以对我们来讲,做微服务的可观察性是要拥抱行业标准的。最早 Open Telemetry 没出来的时候,我自己去设计了一套,把整个链路的深度在框架里面去做了自动检测。但是后来 Open Telemetry 出来以后,咱们还是尽可能地去拥抱行业标准,这样你才可能建立起一个生态。

通过 jaeger 之类的方式,把我们观测的数据呈现出来。正如图上所示,服务 A 调用了服务 B 和服务 C,又有一个统一的 ID 来表示我整个请求所有的链路。同时我能通过 ID 来表示,子请求 1 是调用 B 的,子请求 2 是去调用 C 的,然后 B 去调用 C 之类的等等。在这样设计之下,有问题是很容易被发现的。
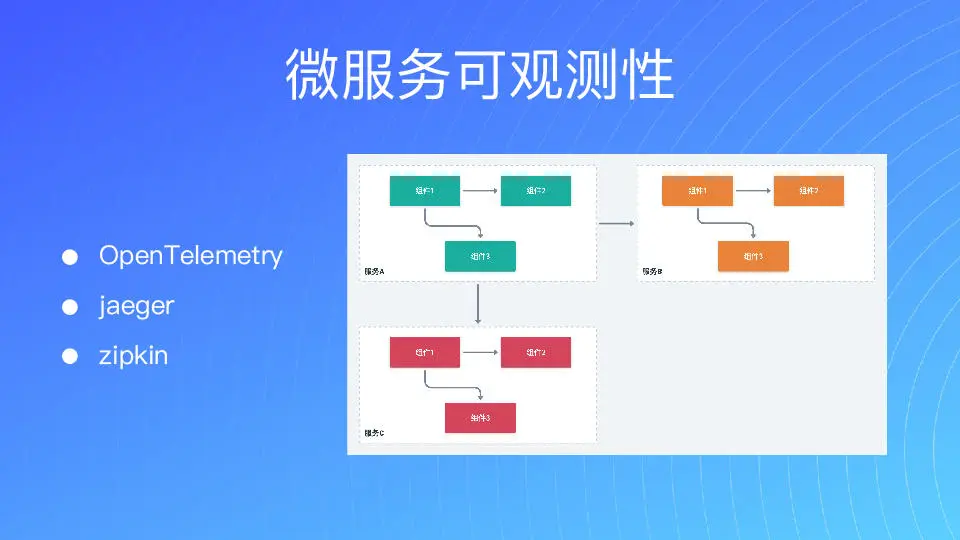
当请求出现的时候,我可以去查看帖子,看到我后面调用了哪些请求,每一个花了多少时间,还可以看详细信息。所以可以说整个确实的信息,在 jaeger 集中呈现。
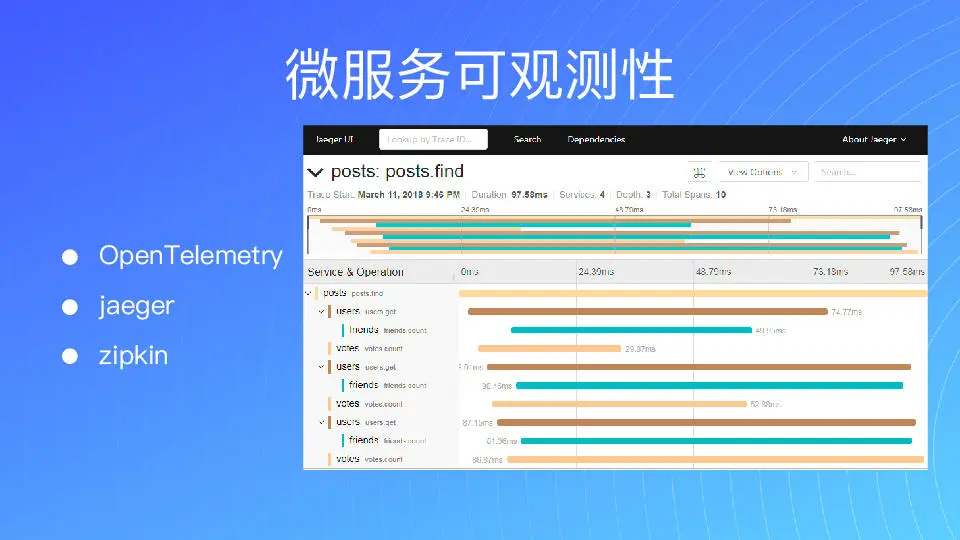
上一期我们讲过要避免环形依赖,其实我们可以通过图中的方式,把整个调用的关系链呈现出来,一目了然。健康报警也要及时送达,同时要减少报警,提高报警的精准度,避免无尽多的报警导致最后大家谁也不看。

架构扩展性
对我们来讲,在做接口的时候,兼容性是非常重要的一个点。因为大家都知道,要让别人从一个老接口切换到新接口,这是非常非常困难的。当你接口设计不好后面要调异常困难。比如说对于 go-zero 来讲,我们有时候要调接口,特别是依赖于第三方的 driver,它以前是没有官方驱动的。大致来讲,这种升级只能保持两份共存,告诉他你鼓励用新的,但是老的你也不能去掉。所以兼容性一定要非常重视。
在设计这个 RESTful API 的时候,有两个典型的因素。第一你要考虑版本,不同的版本需要兼容性。另外要尽可能地针对 resource 资源来定义 API。我一直说我们的微服务是逐步拆分的,假如说你原来的单体中有一块粒度比较粗的服务放在里面,如果说你不能很好地去把里面的资源区分开,那后面很难把服务拆得更细的。因为不管用反向代理用 Nginx 也好,很难去清晰地定义出路由规则。

比如图中所示,架构要尽可能简单,每一层要清晰,而且层要尽可能少一点。我推荐大家不要过多在 Nginx 去搞一系列的事情,搞到最后就是你也不知道问题在哪。
当问题进来以后,查很久也查不出来是为啥,因为每一层都在动这个 request。那这种情况,你遇到问题你真的只能去拆一下,然后不停去找。所以系统出一个问题了,如果 5 分钟之内不能初步定位这个问题在哪,那么这个系统一定有问题的。
保障高并发系统的稳定性
下面我想和大家分享高并发相关的问题。
数据拆分
高并发在 go-zero 里是比较多的,它肯定绕不开数据的问题,因为数据库不对了,那高并发无从谈起。所以我们一定要把数据给隔离清楚,把数据的边界定义清楚。我们对高并发服务是拒绝联合查询的,基本上通过 rpc 来访问。

缓存系统
这里可以和大家分享一个案例,是我群里的一个朋友,他在一个游戏公司,本来每次开服务器只有 6000 人上线,最近新的服务量是原来的 3 倍不到,数据不错,但是服务就挂了。然后我们就立马跟他说,其实你用 go-zero 写的就把你原来代码先拷贝出来,然后你用 go control 生成 model 的时候加“-c”,就给你自动生成缓存了,再把你原来那个复杂的部分放进来,就可以用这个缓存。他用了这个方法之后,第二天跟我们说没问题了,一下上来 16000 也很稳,还开玩笑讲在公司可以横着走了。
所以缓存还是很重要的,大家在做系统的时候要考虑一下。

负载均衡
对高并发系统来讲,处理负载均衡也很重要。负载均衡常用的用法是在 Nginx 加权重,我加一个 weight,然后用 Round Robin 的方式去处理。当有一个节点挂掉的时候,就需要去把这个节点从 Nginx 上摘掉,然后再增加一个节点时,在 Nginx 上再去配。当然 Nginx 加上 live list 是以前比较传统的方式。
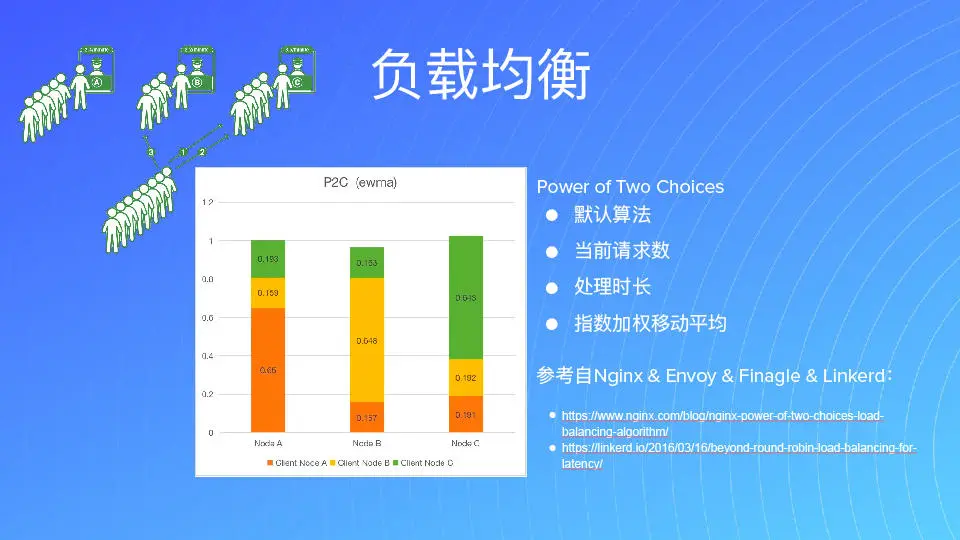
那么现在对我们来讲,首先我们有了服务发现,它会把后面存在的节点上报到注册中心。在 go-zero 中我们可以把后面所有感知到注册上来的节点来做调度,我们记录当前这个节点承载的请求数,然后把每一个节点返回到 response time。这样我们再来去看它的延迟、失败率等数据,如果挂掉了就摘除。
那么摘除后何时再恢复呢?我们原来把所有的集群和所有的机器,均分到五个不同的机房去。这样任何一个机房它有问题,或者某一个节点有问题的时候,我们都是可以很方便地把它自动隔离掉。然后当它恢复的时候,我们又可以把它从负载均衡的池子里恢复出来。所以这个就比较比较智能。对于我们这个负载均衡的机制来讲,秒级的时间就可以自动隔离,自动恢复了。所以这种方式在做架构选型的时候,大家是可以去考虑的。
中间件设计
我们为了架构能够比较好的扩展,尽可能不要把代码都写死在每一个业务里。对公司来讲,很多时候它其实是通用的能力。那如果有统一的中间件方式,就可以通过中间件的方式去提供。对每一个业务线而言,只要公司有中间件它就可以插入进去。这种方式对我们来讲,研发的效率以及可扩展性,都可以通过中间件的方式来实现泛化或者自定义的需求。中间件的设计会让整个系统的扩展性非常好,并且因为中间件上有一些保护机制,所以核心代码是比较稳定的。比如中间件方式有问题,不至于让一个中间件影响整个系统。因为对我们来讲,并发请求是比较强调要对请求级别隔离的,不可能因为一个恶意用户的错误请求把系统搞崩掉,进而影响所有的用户。所以我认为做隔离是很有必要的。
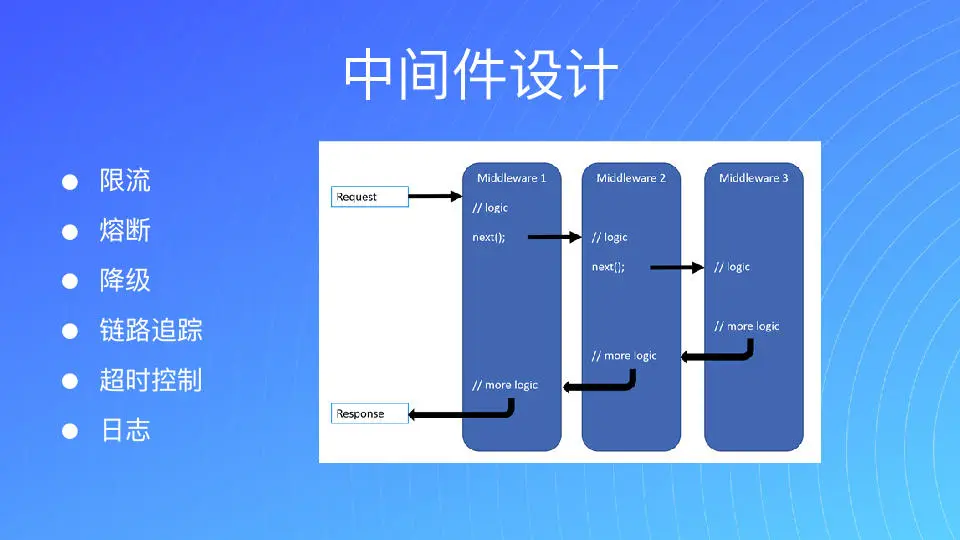
所以对我们来讲,把很多微服务能力都集成在中间件上,比如说限流、熔断、降级、链路跟踪,超时控制、日志等等,我们全是用中间件的方式来给大家实现。图中是一个典型的洋葱模型,一层一层进来然后再出去。

在 GRP 中,也是有中间件的设计的。对我们来讲,刚才说的所有能力也放在其中,当然你也完全可以通过自己的方式,来实现需要的中间件。
自适应熔断
对服务治理而言,还是需要去考虑的就是熔断。当我们后面的 DB 出了问题,或者是某一个服务出了问题,这个时候你打过去请求,你只会增加 DB 的压力,这个时候就需要我们给后面的服务去做一些保护。

那对 go-zero 来讲,我们是把整个熔断做成了比较自动化的,它会自动去侦测我们后面服务的状态,去嗅探后面服务的状态。当服务有问题的时候,还可以去平滑返回给客户一些预置的结果。熔断属于自动去触发和自动恢复的,这个不需要去人为干预。
自适应降载
我们现在的架构,很多时候都是跑在 Kubernetes 这个集群上面。对 Kubernetes 来讲,Kubernetes HPA 就是自动的水平伸缩。那么它的默认的设置,比如说 CPU 长期在 80%。这里我们就要搞清楚什么叫长期?长期就是每 15 秒作为一个时间片进行一次侦测,如果连续 4 个周期都在 80% 上的话,就会触发 HPA。但是触发 HPA 需要两个条件都满足,一个是 80%,第二个是连续 1 分钟。但对于我们高并发服务来说,很多时候我们并不能说 1 分钟的时间能扛过去。因为当请求量过高的时候,比如说前面有 10 个 pod,它们可能都超载了。
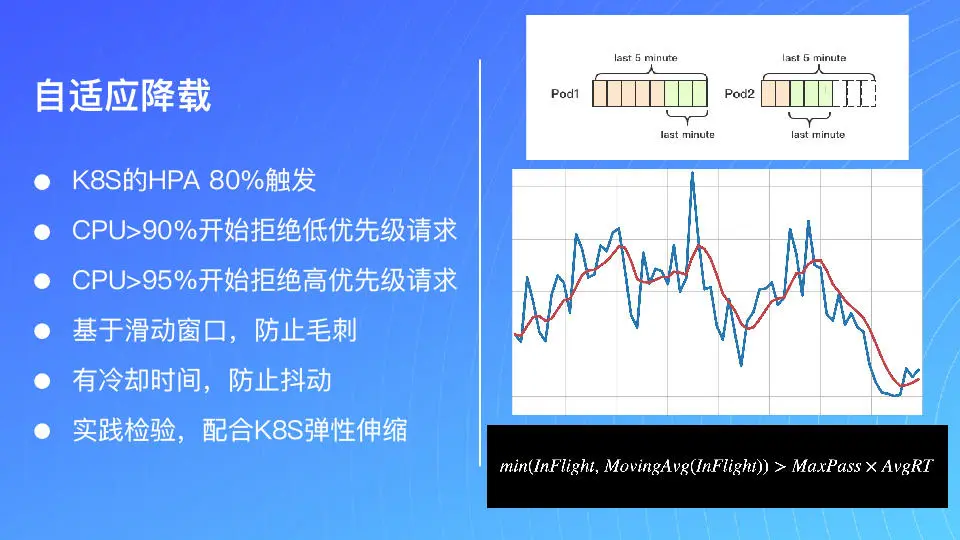
然后当没响应的时候,相当于前面有一个 pod 已经不工作了。不工作我就会自动把它摘掉。比如说我原来 10 个全挂了,我只是起来一个,我可能压到一个新的上面来,十有八九也会被打掉。所以说这个比较好一点的做法是先要让前面的 pod 活下来,我们要主动判断请求是否已经处于过载的状态,如果过载了,我就需要把这个超量的请求先屏蔽掉。
那么这种方式,就可以保障 Kubernetes HPA 能够比较好地去生效,这个方式也在 go-zero 里面自动集成,大家可以去直接使用。
缓存分发算法
对我们高并发服务来讲,不光是我们的缓存分发算法,它也是在架构上可能使用的方案。在一些游戏场景中,有的时候我们需要把它一致性地分发到某一个服务器上去,那对缓存来讲,不同的人对同一个 key 的请求,肯定要投到同一个缓存节点上去,否则就很难保证数据的一致。你也不知道这个缓存在哪,量大了以后,每一个 key 都落到每一个节点上去了。所以缓存分发是我们经常使用的一个算法。举个例子,假如我原来有 5 个节点,那么现在请求过来扩大到 6 个节点,原来所有的请求在 1 到 5 是不变的,假如从 1 开始,1 到 5 是不变的,第 6 个本来在 1 上面,它现在调到 6 上面去了,整个后面都是错的,什么时候能对呢?5 和 6 最小的公倍数,第 30 个请求又会对,相当于后面是六分之一的请求是对的,其他都是错的,整个系统的抖动就非常大。假如我 6 个再加到 7 个,那只有七分之一的请求落在原来的节点上面,大部分都是不会落在原来的节点上面。

那么对于一致性分发算法怎么理解呢?就是首先假如我有 2 个请求,有 2 个节点,如果新增一个节点只有一半会去迁移。那么对于我们来讲,一般常用的算法都带虚拟节点,比如上图右下角,我这只有 3 个节点分别分布在整个虚拟的环上面。虚拟环上面如果再加一个蓝色节点,蓝色节点又会均匀分布在这个环上面。我们在 go-zero 上面是默认 100 个虚拟节点,这样你就可以比较好地分布在这个环上面,随便怎么加都可以来承载。比如说还是左边一样 5 个,我变成 6 个节点,我只有六分之一数据要发生迁移,如果我缩回来,6 个变成 7 个,那我只有七分之一的数据发生迁移。这种抖动对整个系统来讲是小的。
而在这个过程中,首先请求进来以后先去做并发控制,然后去做限流。限流做好了以后,我们就会有自适应的降载,保障我们的集群不会挂掉,然后配合 Kubernetes 弹性伸缩,就能保证整个集群因为有流量波峰过来,导致整个服务的不稳定。
我们通过自适应的熔断,配合负载均衡就可以有效保护后面的服务,当有问题的节点出现,我不会再给它增加额外的压力,还会让它争取一些恢复的时间,用多重防护来保证高可用。

更多治理思考
关于治理,还有很多值得我们思考。
比如说超时,这方面需要我们额外注意。在超时的时候,不能说我前面入口设了 2 秒,后面设个 3 秒就没有意义。那我前面用掉 1 秒,我往后面调的时候也只剩下 1 秒,我总共 2 秒称之为集联超时。就是你要把整个链路上的超时时间串联起来,然后还要跟客户端做一些配合。
另外一般情况下我们不太会人为地重试,采用系统自动重试的比较多。但是我希望尽可能用人为的方式。如果你这个业务需要重试,要做指数的退避。就是不能连续打好几个请求过去,系统可能会把它打挂了。你如果要做得比较细致,需要规划出服务给它多少,比如说我只花 10%,那我 90% 要服务于正常的业务,一旦超过了,对不起请重试请求,因为首先要保证业务的稳定性。

另外重试也有相关性,就是你重试要管超时,万一超时了还在重试,就没有意义了。

