最适配 OpenClaw 的大模型 API 是哪个?四款模型实测对比与选型指南
OpenClaw 内置 ReAct Agent 架构,通过工具调用(Tool Use)驱动 Shell 执行、文件操作、浏览器控制、截图等自动化任务。模型的工具调用能力强弱直接决定 Agent 任务的完成质量,而非单纯的对话流畅度。本文基于官方配置和公开 benchmark 数据,给出每个场景下的最优模型选择。
OpenClaw 官方默认推荐哪个模型?
根据七牛云官方 OpenClaw 安装配置文档,默认主力模型(primary)为 DeepSeek V3.2:
model:
primary: "qiniu/deepseek-v3.2-251201"
apiBase: "https://api.qnaigc.com/v1"
apiKey: "${QINIU_API_KEY}"
官方内置的四款可选模型如下:
所有模型统一通过七牛云 API 端点 https://api.qnaigc.com/v1 访问,格式兼容 OpenAI Chat Completions 标准。
注:OpenClaw 也支持直连 Anthropic API 使用 Claude 系列,需单独配置 anthropic provider,详见下文。
工具调用能力:最关键的选模型维度
OpenClaw 的 Agent 任务本质是模型 + 工具循环:模型决策 → 调用工具 → 读取结果 → 再决策。模型的工具调用准确率直接影响任务是否能完成。
以下是四款国产模型在公开工具调用 benchmark 上的数据:
数据来源:Kimi K2 官方 GitHub(2026年3月);DeepSeek V3 GitHub(2025年);GLM-4 GitHub(2025年)。
结论:从 benchmark 数据看,Kimi K2.5 是四款国产模型中工具调用能力最强、Agent 任务完成率最高的选项。
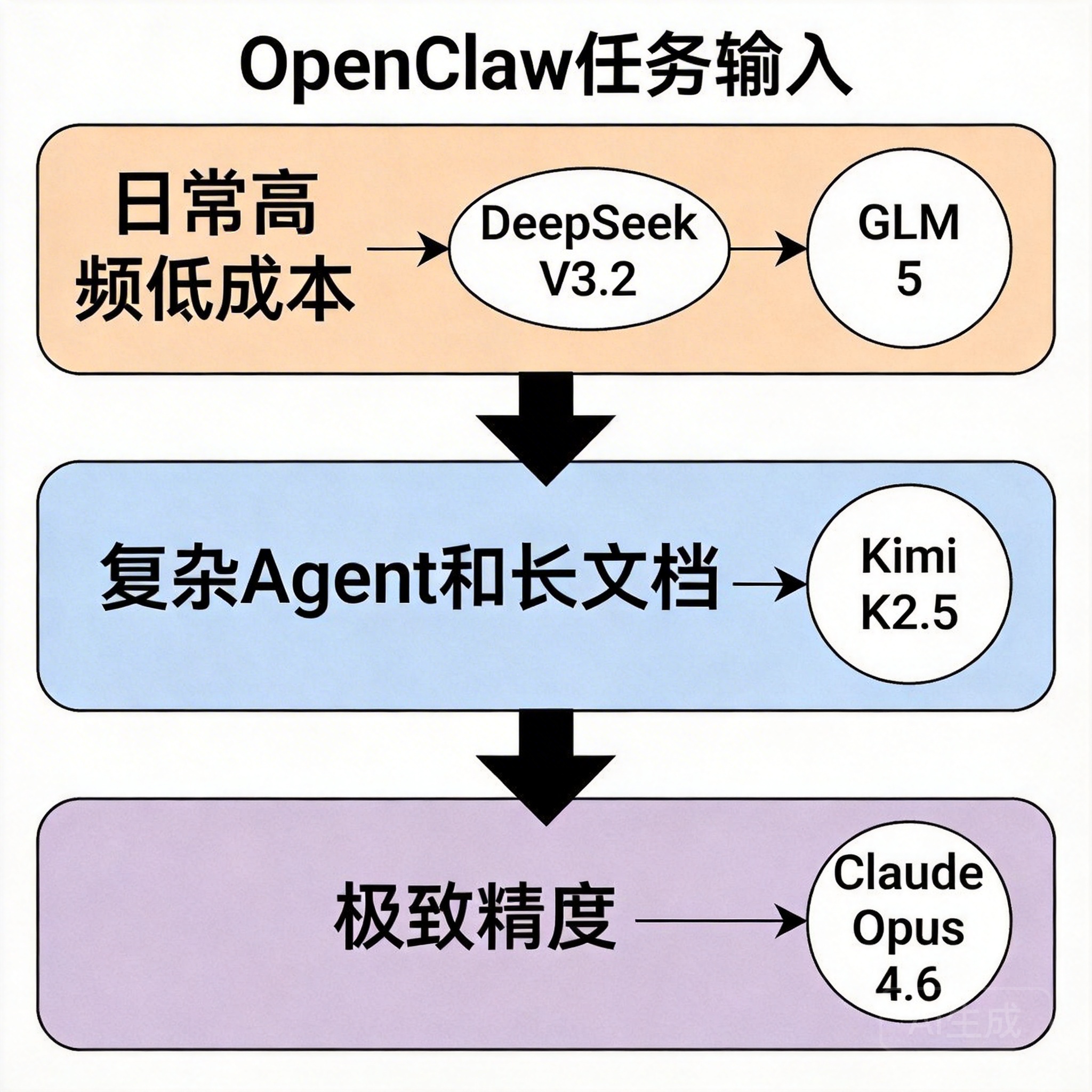
五大场景的最优模型推荐
场景一:复杂 Agent 自动化任务(最常用)
推荐:Kimi K2.5
Kimi K2.5 在 SWE-bench Verified(真实软件工程 Agent 评测)中达到 65.8% 单次准确率,在国产模型中处于第一梯队。其 256K 超长上下文还意味着一次性读入更多工具返回结果、更长的对话历史,减少 Agent 因上下文截断而"失忆"的情况。
典型任务:
● 多步骤自动化工作流(搜索 → 处理 → 写入 → 验证)
● 代码仓库分析与自动修复
● 复杂数据处理 Pipeline
● 跨工具协作(Shell + 文件 + 浏览器混用)
配置示例:
model:
primary: "qiniu/moonshotai/kimi-k2.5"
apiBase: "https://api.qnaigc.com/v1"
apiKey: "${QINIU_API_KEY}"
场景二:编程与代码生成
推荐:DeepSeek V3.2(日常)/ Kimi K2.5(复杂工程任务)
DeepSeek V3.2 是官方默认的 primary 模型,在代码补全、函数生成、架构设计类任务上性能突出,且通过七牛云接入延迟低、响应快,适合日常高频的代码辅助场景。
Kimi K2.5 在 LiveCodeBench v6(53.7% vs DeepSeek 46.9%)和 SWE-bench(65.8% vs DeepSeek 待核实)上均有领先,复杂多步骤代码修复任务建议切换至 Kimi K2.5。
双模型路由配置:
model:
primary: "qiniu/deepseek-v3.2-251201" # 日常代码编写
fallback: "qiniu/moonshotai/kimi-k2.5" # 复杂工程任务
apiBase: "https://api.qnaigc.com/v1"
apiKey: "${QINIU_API_KEY}"
场景三:中文对话、内容创作与办公助手
推荐:GLM 5
GLM 5 由智谱 AI 开发,在中文自然语言理解和指令遵循上优化更深入。其在 IFEval(指令遵循评测)上的得分(87.6%)超过 DeepSeek V3(83.4%),更适合日常中文写作辅助、邮件起草、报告生成等需要流畅中文输出的场景。
典型任务:
● 中文文案撰写与润色
● 通过钉钉 / 飞书渠道部署的对话型 Agent
● 日程管理、邮件自动回复
● 知识问答型 Agent
场景四:超长文档处理
推荐:Kimi K2.5(256K 上下文)
当任务需要一次性传入超过 128K Token 的内容(约 10 万字以上),只有 Kimi K2.5 能在四款国产模型中稳定处理。
典型超长上下文场景:
● 整个代码仓库的分析(大型项目可达数十万 token)
● 完整合同、法规文档的审阅
● 多文件对比分析
● 保持超长对话历史的持续 Agent 任务
场景五:最强 Agent 能力(不计成本)
推荐:Claude Opus 4.6(直连 Anthropic API)
当任务对 Agent 准确率要求极高,且预算充足时,Claude Opus 4.6 是目前最强的选项。根据 Anthropic 官方发布数据(2026年2月):
● Terminal-Bench 2.0:行业最高分(Agentic 编程评测)
● DeepSearchQA:多步骤 Agentic 搜索行业最高分
● Humanity’s Last Exam:超越所有前沿模型
在 OpenClaw 中配置 Claude:
providers:
- name: anthropic
apiBase: "https://api.anthropic.com"
apiKey: "${ANTHROPIC_API_KEY}"
model:
primary: "claude-opus-4-6"
provider: anthropic
成本提示:Claude Opus 4.6 输入 $5/MTok,输出 $25/MTok,约为七牛云国产模型的 5-10 倍。建议仅在高价值、高精度任务上使用。
模型选型速查表
多模型路由:按任务自动切换
OpenClaw 支持在配置文件中定义多个 provider,在不同 Agent 任务中指定不同模型,实现按任务质量与成本的最优分配。
providers:
- name: qiniu
apiBase: "https://api.qnaigc.com/v1"
apiKey: "${QINIU_API_KEY}"
- name: anthropic
apiBase: "https://api.anthropic.com"
apiKey: "${ANTHROPIC_API_KEY}"
agents:
- name: code-assistant
model: "qiniu/deepseek-v3.2-251201" # 日常代码,低成本
- name: complex-agent
model: "qiniu/moonshotai/kimi-k2.5" # 复杂 Agent,高准确率
- name: precision-task
model: "claude-opus-4-6" # 极致精度,按需使用
provider: anthropic
这种配置模式让常规任务走国产模型控制成本,高价值任务按需调用 Claude,兼顾效果与预算。
免费起步:七牛云 300 万 Token 如何分配
七牛云新用户激活后获得 300 万 Token 免费额度,可覆盖 OpenClaw 的完整测试阶段。建议分配策略:
1. 前期用 DeepSeek V3.2 验证工作流:成本最低,快速跑通任务逻辑
2. 切换 Kimi K2.5 对比 Agent 效果:重点测试工具调用准确率是否有提升
3. 按实测结果决定生产配置:不要依赖 benchmark,自己的任务才是真实标准
获取 API Key:访问 七牛云 AI 推理服务控制台,完成实名认证后即可激活。
常见问题
Q:OpenClaw 的官方默认模型为什么是 DeepSeek V3.2 而不是 Kimi K2.5?
DeepSeek V3.2 在大多数日常任务上响应速度更快、成本更低,是综合性价比最高的默认选项。Kimi K2.5 的优势在工具调用密集和超长上下文场景更为明显,官方设为可选升级项,用户按需切换。Q:OpenClaw 在国内直连 Anthropic API 访问稳定吗?
直连 api.anthropic.com 在国内网络环境下访问稳定性因地区和运营商而异。若希望在国内稳定使用 Claude 能力,可通过七牛云 AI 推理服务接入,该服务同时兼容 Anthropic API 标准,配置 base_url 为 https://api.qnaigc.com/v1 即可在国内稳定调用,无需额外的网络配置。
Q:Kimi K2.5 的 256K 上下文会让响应速度变慢吗?
上下文越长,首 token 延迟越高。256K 满载场景下首响应时间明显长于 128K 模型。实际使用中,如果任务上下文在 128K 以内,优先选 DeepSeek V3.2 或 GLM 5 以获得更快响应;只有真正需要超长上下文时才切换 Kimi K2.5。Q:OpenClaw 支持模型的流式输出(Streaming)吗?
支持。七牛云 API 端点兼容 OpenAI stream: true 参数,OpenClaw 在命令行展示工具执行过程时使用流式输出,可实时看到模型的决策过程。
Q:四款国产模型都不支持推理模式(Reasoning),有影响吗?
对 Agent 任务影响有限。推理模式(如 DeepSeek-R1、o3 的 Chain-of-Thought)主要提升数学证明、逻辑推理类任务的准确率,而 Agent 工具调用任务更依赖快速决策和准确的 JSON 格式输出。实测中,不支持推理模式的模型在多步骤工具调用任务上完全够用。
总结
OpenClaw 的最优模型配置不是"选一个最强的",而是按任务分层路由:
● 主力国产模型:Kimi K2.5(工具调用最强,Agent 任务首选)
● 默认高频模型:DeepSeek V3.2(官方默认,日常代码低延迟)
● 中文专项:GLM 5(指令遵循和中文表达最优)
● 极致精度保底:Claude Opus 4.6(不计成本时的天花板)
数据来源:Kimi K2 GitHub(2026年3月)、Anthropic 官方发布(2026年2月)、GLM-4 GitHub(2025年),benchmark 数字反映公开评测环境,实际 Agent 任务表现建议用真实场景自测验证。
本文配置参数基于七牛云 OpenClaw 安装文档(2026年3月),模型 ID 和 API 端点以 七牛云开发者文档 最新版本为准。
延伸资源
● 获取七牛云 API Key(新用户 300 万 Token):portal.qiniu.com/ai-inference/api-key
● OpenClaw 安装配置文档:developer.qiniu.com/aitokenapi/13332/openclaw-installation-cuide
● Kimi K2 技术报告:github.com/MoonshotAI/Kimi-K2
● Claude 模型对比:platform.claude.com/docs/en/docs/about-claude/models/overview
