大模型微调平台怎么选?2026 主流开源框架与云平台全景对比
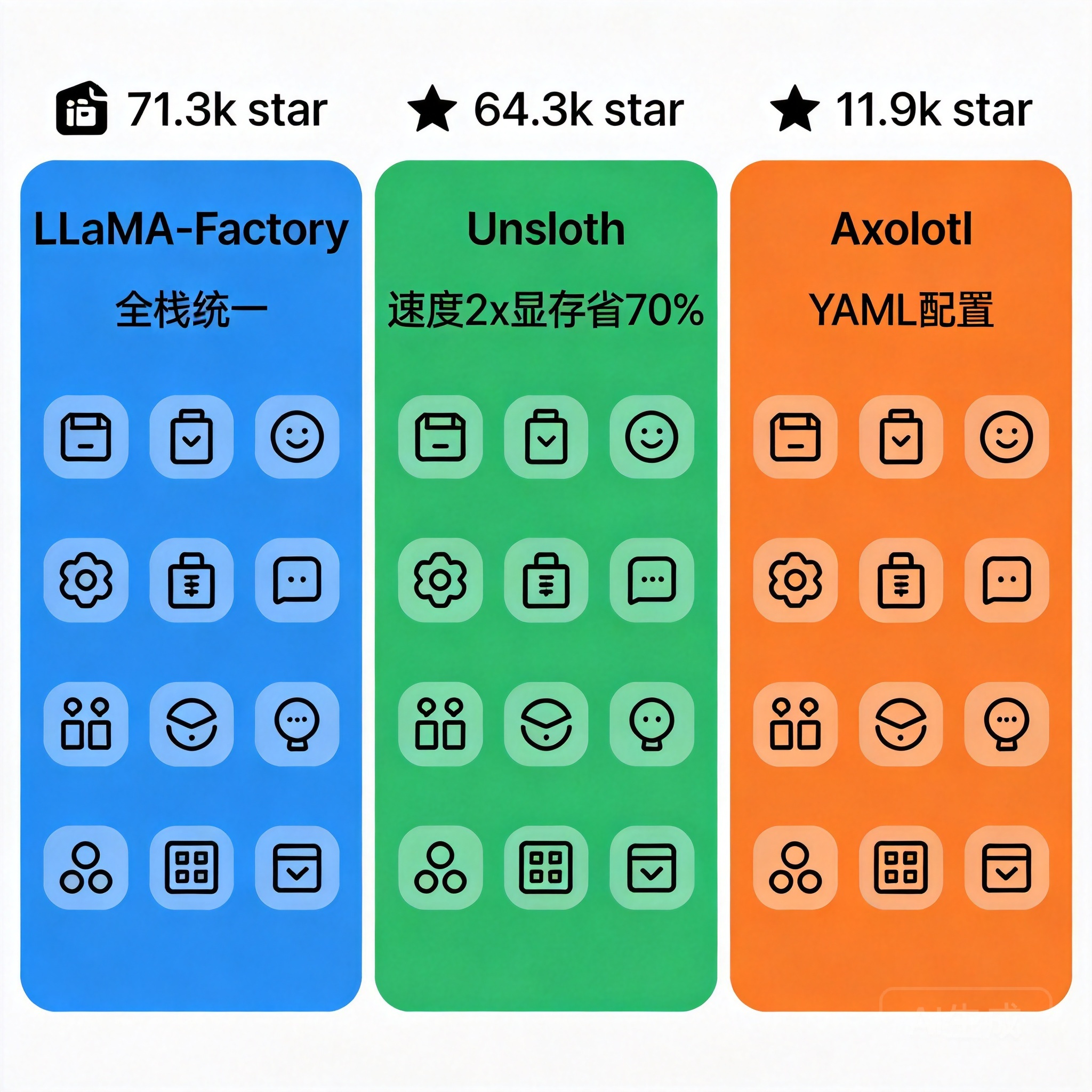
大模型微调平台是为企业和开发者提供 LLM 定制化训练能力的工具系统,2026 年已形成"开源框架"与"云端 MaaS 平台"两大阵营。开源阵营以 LLaMA-Factory(71.3k stars)、Unsloth(64.3k stars)、Axolotl(11.9k stars)为代表;云平台阵营则由阿里百炼、火山方舟、七牛云大模型 API 等提供托管化微调服务。选型核心取决于团队的算力规模、技术栈深度与合规要求。
一、大模型微调平台的核心定义
大模型微调平台是为预训练大模型(LLM/VLM)提供继续训练能力的工具体系,通过 SFT(监督微调)、LoRA、QLoRA、DPO、GRPO 等方法,将通用模型适配到具体业务场景。
三类典型微调任务
● 指令微调(SFT):让模型学会按特定格式回答(如客服话术、医疗诊断)
● 偏好对齐(DPO / GRPO / KTO):基于人类反馈对齐输出风格与价值观
● 领域适配(继续预训练):在医疗、金融、法律等垂直领域语料上继续训练
微调 vs RAG vs 提示工程
二、2026 主流开源微调框架对比
开源微调框架的三大主角分别代表了三种技术哲学:LLaMA-Factory(大而全)、Unsloth(快而省)、Axolotl(灵活可组合)。
2.1 LLaMA-Factory:全栈统一微调框架
核心数据(来自 GitHub 官方):
● GitHub Star:71.3k(8.7k forks,ACL 2024 论文项目,Apache-2.0 许可)
● 支持模型:100+,涵盖 LLaMA、Qwen3 / Qwen3-VL、DeepSeek、Gemma 3、GLM-4.5、Mistral / Mixtral、Phi-4、InternVL、Llama 4、GPT-OSS
● 训练方法:预训练 / SFT / 奖励建模 / PPO / DPO / KTO / ORPO / SimPO
● 微调方式:全参 / Freeze / LoRA / QLoRA(2/3/4/5/6/8-bit)/ OFT / QOFT
● 加速集成:FlashAttention-2、Unsloth、Liger Kernel、KTransformers
● 使用方式:CLI(llamafactory-cli)、LLaMA Board Web UI(Gradio)、Docker(CUDA / Ascend NPU / AMD ROCm)
● 采用方:Amazon、NVIDIA、Aliyun 等已采用
# LLaMA-Factory LoRA 微调命令示例
llamafactory-cli train \
--stage sft \
--model_name_or_path Qwen/Qwen3-7B \
--dataset alpaca_zh \
--finetuning_type lora \
--lora_target all \
--output_dir ./output
最低硬件门槛:7B 模型 4-bit QLoRA 仅需 6GB 显存——这是它能成为最广泛使用的微调框架的关键。
2.2 Unsloth:训练速度与显存优化王者
核心数据(来自 GitHub 官方):
● GitHub Star:64.3k(5.7k forks)
● 核心承诺:训练 500+ 模型,速度提升最高 2x,显存节省最高 70%,无精度损失
● 平台支持:Windows、Linux、WSL、macOS
● MoE 模型加速:训练加速 12 倍,显存减少 35%(适用于 DeepSeek、GLM、Qwen、gpt-oss)
● 长上下文支持:80GB GPU 上可对 20B 模型进行 500K 长上下文训练
数据来源:Unsloth GitHub README(2026 年 5 月)
适合场景:消费级 GPU(如 RTX 4090 / 5090)微调 7B-70B 模型,需要把 token / 秒做到极限的团队。
2.3 Axolotl:配置驱动的灵活框架
核心数据(来自 GitHub 官方):
● GitHub Star:11.9k(1.3k forks,Apache-2.0)
● 支持微调技术:Full / LoRA / QLoRA / GPTQ / QAT(含 NVFP4)/ DPO / IPO / KTO / ORPO / GRPO / GDPO / RM / PRM
● 性能优化:Flash Attention 2/3/4、Xformers、Flex Attention、SageAttention、Liger Kernel、Cut Cross Entropy、ScatterMoE
● 并行训练:Sequence Parallelism(SP)、ND Parallelism(CP + TP + FSDP 组合)、FSDP1 / FSDP2 / DeepSpeed
● 多模态:LLaMA-Vision、Qwen2-VL、Pixtral、LLaVA、Voxtral 音频模型
● 环境要求:Python ≥ 3.11、PyTorch ≥ 2.9.1、NVIDIA Ampere+ 或 AMD GPU
核心优势:单个 YAML 配置文件贯穿数据预处理、训练、评估、量化、推理全流程,适合需要严格实验复现的研究团队。
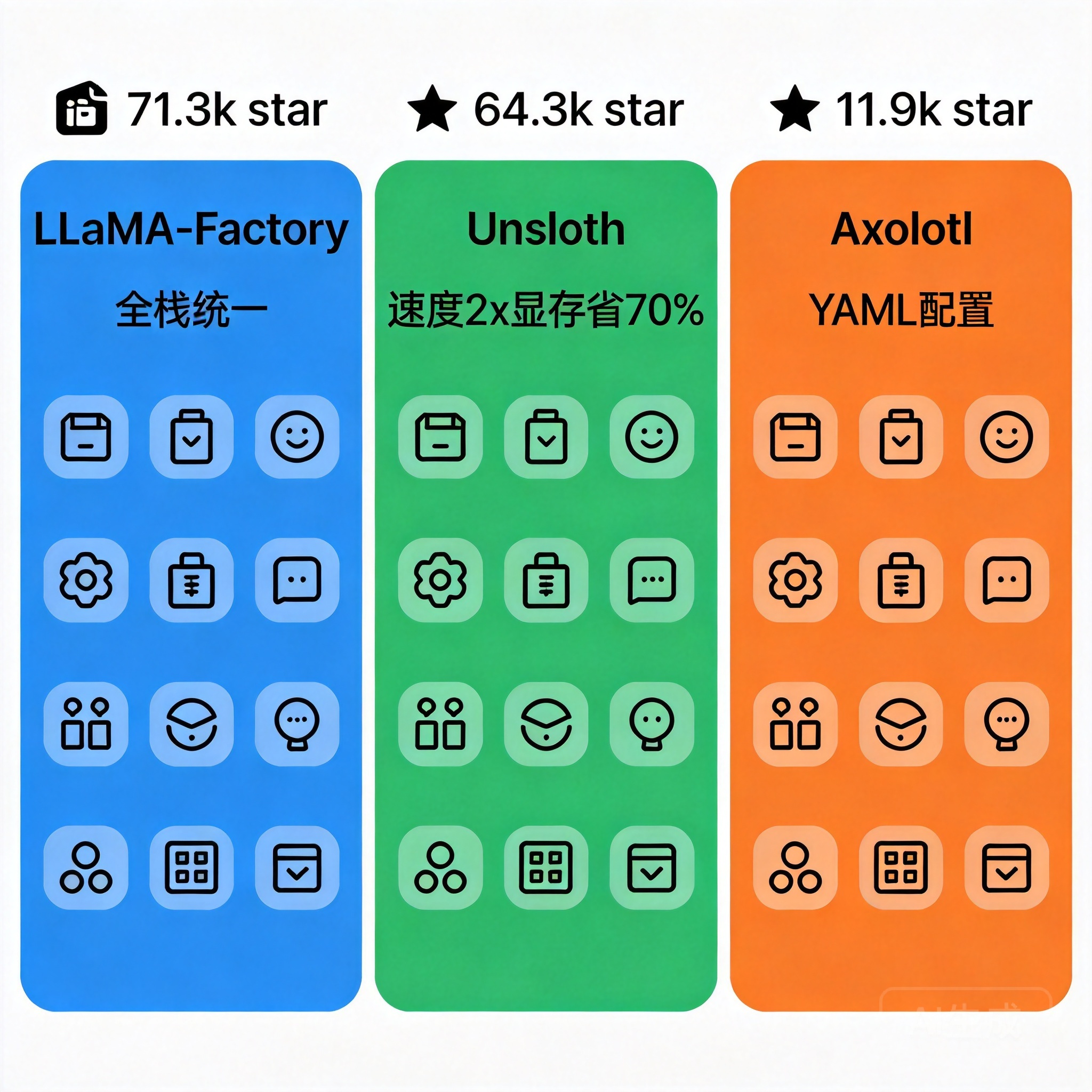
三、开源框架横向对比表
三大开源框架在不同维度的表现差异显著:
数据来源:三个项目 GitHub README(2026 年 5 月)
四、云端微调平台对比
云端微调平台的核心价值是"算力 + 数据 + 部署"一体化,免去自购 GPU 与运维成本。
4.1 主流云端微调服务
4.2 开源框架 + 云平台的混合方案
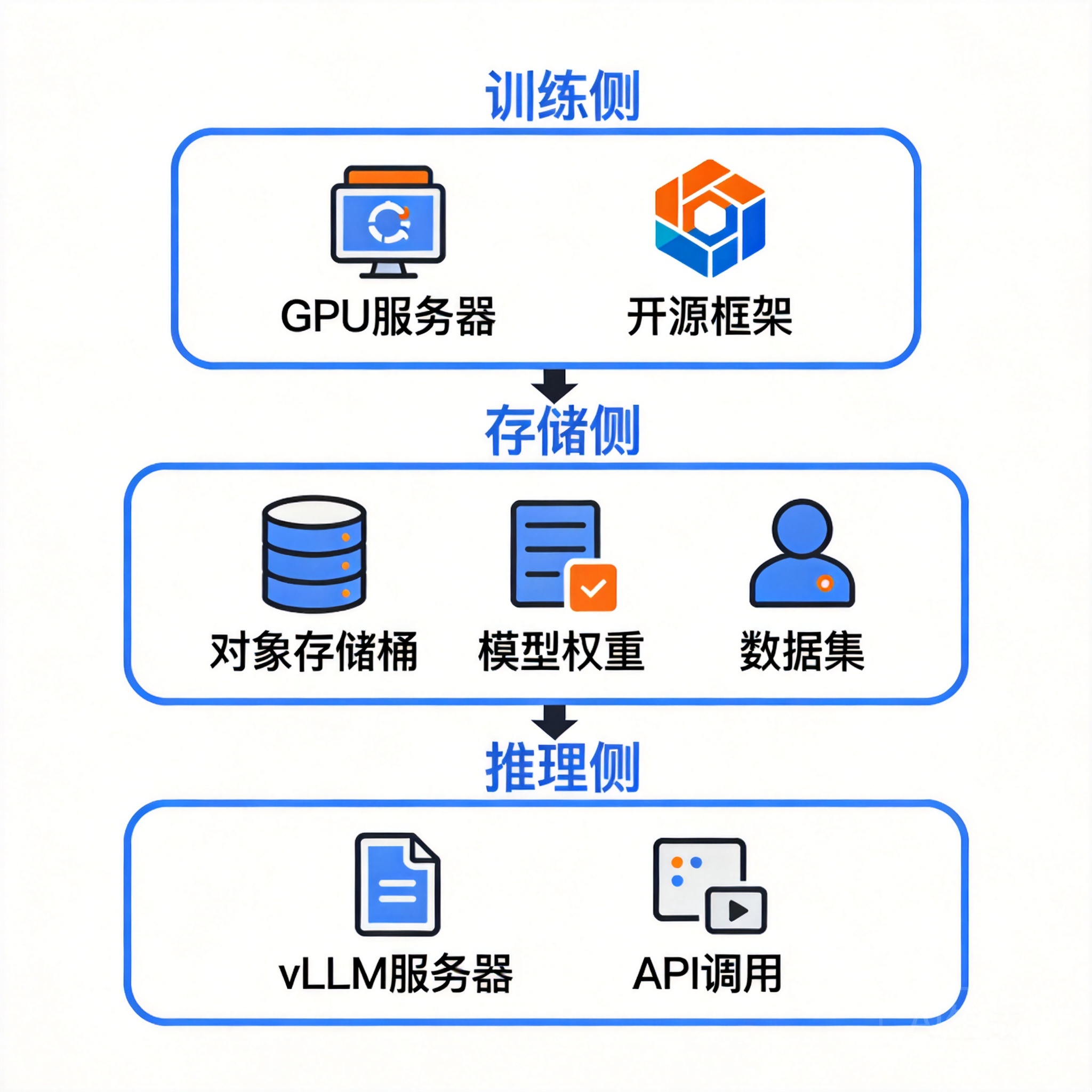
生产环境最佳实践通常是"开源框架做训练 + 云平台做推理":
┌──────────────────────────────────────────────┐
│ 训练侧:LLaMA-Factory / Unsloth / Axolotl │
│ ↓ 产出 LoRA 权重 / 微调后完整模型 │
├──────────────────────────────────────────────┤
│ 存储侧:对象存储(权重 + 数据集 + 日志) │
│ ↓ 模型分发 │
├──────────────────────────────────────────────┤
│ 推理侧:vLLM / SGLang / 云端 MaaS API │
└──────────────────────────────────────────────┘
例如开发者用 LLaMA-Factory 在自有 GPU 上完成 Qwen3 微调,把权重存到对象存储,再通过 vLLM 部署推理服务——七牛云大模型 API 即支持这种"自有微调模型 + 多模型聚合推理"的混合接入,通过对象存储 Kodo 实现训练数据与模型权重的统一管理。
五、企业微调平台选型决策树
选型应按"算力规模 → 团队能力 → 合规要求 → 推理路径"四步决策。
5.1 按算力规模选
● 单卡消费级 GPU(RTX 4090 / 5090,24-32GB):Unsloth + QLoRA,这是性价比最高的组合
● 单机多卡(8×A100 / H100):LLaMA-Factory 或 Axolotl,支持完整的全参微调
● 多节点训练集群:Axolotl(ND Parallelism)或 LLaMA-Factory(Megatron-core 后端)
5.2 按团队能力选
● 算法工程师 + 研究团队:Axolotl(YAML 可控性最强,适合实验复现)
● 应用工程师 + 产品团队:LLaMA-Factory(Web UI 友好)或 Unsloth Studio
● 非技术团队 / 业务方 PoC:云端托管(阿里百炼 / 火山方舟 / Hugging Face AutoTrain)
5.3 按合规要求选
● 数据完全本地化:开源框架自建集群(LLaMA-Factory / Axolotl)
● 国内合规备案:阿里百炼、火山方舟、七牛云大模型 API
● 跨境 / 多区域:AWS Bedrock、Azure OpenAI
5.4 按推理路径选
微调完成后,推理路径决定了存储与服务架构:
● 自托管推理:用 vLLM / SGLang 部署微调后模型,需要 GPU 集群与运维投入
● 托管 API 推理:把微调后模型托管到云平台,按 token 计费,免运维
● 混合推理:简单请求路由到通用模型 API(如 DeepSeek-V4-Flash 0.001 元/K tokens),复杂请求路由到自有微调模型
六、典型微调场景与平台匹配
不同场景下的最佳平台组合差异显著:
场景 A:垂直行业知识助手(医疗 / 法律 / 金融)
● 训练:Axolotl + QLoRA(数据严格隔离,YAML 可审计)
● 数据:本地存储,不出域
● 推理:自建 vLLM 集群或私有化部署
场景 B:客服话术风格适配
● 训练:LLaMA-Factory + LoRA(SFT + DPO 流程完整)
● 数据:对象存储托管
● 推理:云端 API,按调用量付费
场景 C:小团队快速 PoC
● 训练:Unsloth + Google Colab(免费 T4 GPU)
● 数据:Hugging Face Datasets
● 推理:模型聚合 API(便于 A/B 测试不同 base 模型)
场景 D:多模型矩阵评测
● 训练:LLaMA-Factory(同一框架训 Qwen / DeepSeek / Llama)
● 推理:支持 OpenAI/Anthropic 双协议兼容的聚合 API,单 Key 切模型 AB 测试
七、常见问题
Q1:LLaMA-Factory、Unsloth、Axolotl 怎么选?
看团队优先级:追求模型覆盖最广 + Web UI 友好选 LLaMA-Factory(71.3k star,100+ 模型);追求训练速度与显存极限选 Unsloth(64.3k star,2x 加速、70% 省显存);追求配置可控与实验复现选 Axolotl(11.9k star,YAML 驱动)。三者并非互斥——LLaMA-Factory 内置集成了 Unsloth 作为加速后端。
Q2:7B 模型微调最少需要多少显存?
LLaMA-Factory 官方公示数据:7B 模型 4-bit QLoRA 仅需 6GB 显存;Unsloth 在同等条件下显存进一步降低 50-70%,意味着 RTX 3060 12GB 即可微调 7B 模型,RTX 4090 24GB 可微调 14B-32B 模型。
Q3:微调后的模型如何部署到生产?
三种主流路径:(1)自建 vLLM / SGLang 服务,需 GPU 集群;(2)上传到云端 MaaS 平台托管,按 token 计费;(3)合并 LoRA 权重后导出 GGUF / AWQ 量化版本,用 Ollama / llama.cpp 本地部署。生产环境建议结合多模型聚合 API,简单请求走通用模型、复杂请求走自有微调模型。Q4:DPO、GRPO、ORPO 这些 RLHF 方法选哪个?
● DPO(Direct Preference Optimization):最广泛使用,训练稳定,LLaMA-Factory / Unsloth / Axolotl 都支持
● GRPO:DeepSeek R1 同款,适合推理类任务,Unsloth 与 Axolotl 原生支持
● ORPO / SimPO:更省算力的偏好对齐变体,LLaMA-Factory 完整覆盖
● KTO:数据需求最低(只需二元偏好),适合数据稀缺场景
Q5:云端微调与自建微调的成本临界点在哪?
经验法则:单月微调任务量 < 10 次的团队,云端托管更划算(免 GPU 折旧、免运维);> 50 次或持续训练的团队,自建 GPU 集群 + 开源框架成本优势明显。中间区间(10-50 次)建议采用混合方案——用云端 GPU 实例(按时计费)运行开源框架。
八、总结
大模型微调平台 2026 年已进入开源框架 + 云端 MaaS 双轨并行的成熟阶段。开源阵营的 LLaMA-Factory(71.3k star)、Unsloth(64.3k star)、Axolotl(11.9k star)分别代表全栈统一、速度极致、配置灵活三种技术路线;云端阵营则提供从训练到推理的一体化托管。企业选型应回归算力规模、团队能力、合规要求、推理路径四个核心维度——对绝大多数中国企业而言,"开源框架做训练 + 国产大模型聚合 API 做推理"的混合方案,在成本、合规与灵活性上取得最佳平衡。
据 Hugging Face 2026 年开源模型生态报告分析,LoRA / QLoRA 已成为企业微调的主流方式,占新发布微调模型的 80% 以上。本文内容基于 2026 年 5 月各项目官方 README 与平台公示数据(LLaMA-Factory 71.3k stars、Unsloth 64.3k stars、Axolotl 11.9k stars),建议结合最新版本动态决策。
延伸阅读:
● 多模型推理 API 与微调模型托管:七牛云 AI 大模型广场
