大模型 API 适合哪些业务场景:从 Anthropic 自己公布的 17 个真客户里看出来的规律
我刚把 Anthropic 官网 claude.com/customers 这页从头到尾翻了一遍。这页是 2026 年 5 月的现状,列着十几家正式公布姓名的客户和他们用 Claude API 在做的事——Notion、Slack、Figma、HubSpot、Pendo、Vapi、Rogo、OpusClip、Reversia、Smartsheet、Artemis、Gradial、Bolt、Delivery Hero、AirOps、Bubble、Mutiny。
把这 17 个案例放在一起看,你会发现一个有趣的规律:真正在大模型 API 上花钱并且持续用下去的业务场景,全都长一个样——它们要么是替人重复看东西,要么是替人重复写东西,要么是替人重复做决策。听起来像废话,但这句话是有刀的,下面我把它切开。
替人重复看东西:客户支持、安全运营、合规审查
这是最早被打透的赛道,也是 2026 年依然在收钱的赛道。
Slack 用 Claude 做"AI search and summaries"——员工在 Slack 里搜东西、总结频道、回顾会议纪要,本质都是让模型"看"完海量历史消息再吐出一句话。Artemis 这家做安全的,自己披露的数字是"帮安全团队把事件解决时间砍掉 96%"——一个安全告警通常要工程师扒一堆日志、Jira、PR、Slack 上下文,模型替他们扒完了。
逻辑在哪?人看 100 条消息要 30 分钟,模型看 100 条消息要 30 秒,准确率还不输。这个 ROI 算不烂。客户支持也是一样——HubSpot 在他们的客户故事里讲怎么"reclaim time for creativity",潜台词就是把回复工单、检索知识库这些"看东西"的活给了模型。
替人重复写东西:销售、营销、内容生产
Mutiny 的描述特别精炼——“gives every seller a full creative team”。意思是销售本来要靠创意团队帮他写邮件、做落地页、改文案,现在 Claude 一对一陪着每个销售。Reversia 把电商店铺"翻译成 110+ 种语言"——这是另一种重复写。OpusClip 用 Claude Code 搭它的 GTM(go-to-market)引擎,跟 Mutiny 是同一个套路。
这条赛道的关键不是"模型能写"——三年前的 GPT-3 也能写。关键是 2026 年的模型已经能在写之前先把客户档案、产品文档、品牌调性吃进去。所以 Mutiny 不是"自动写邮件工具",是"知道你这单跟进了 5 次、对方公司刚拿了 B 轮、上次提过预算紧、所以这次邮件应该这样写"的工具。
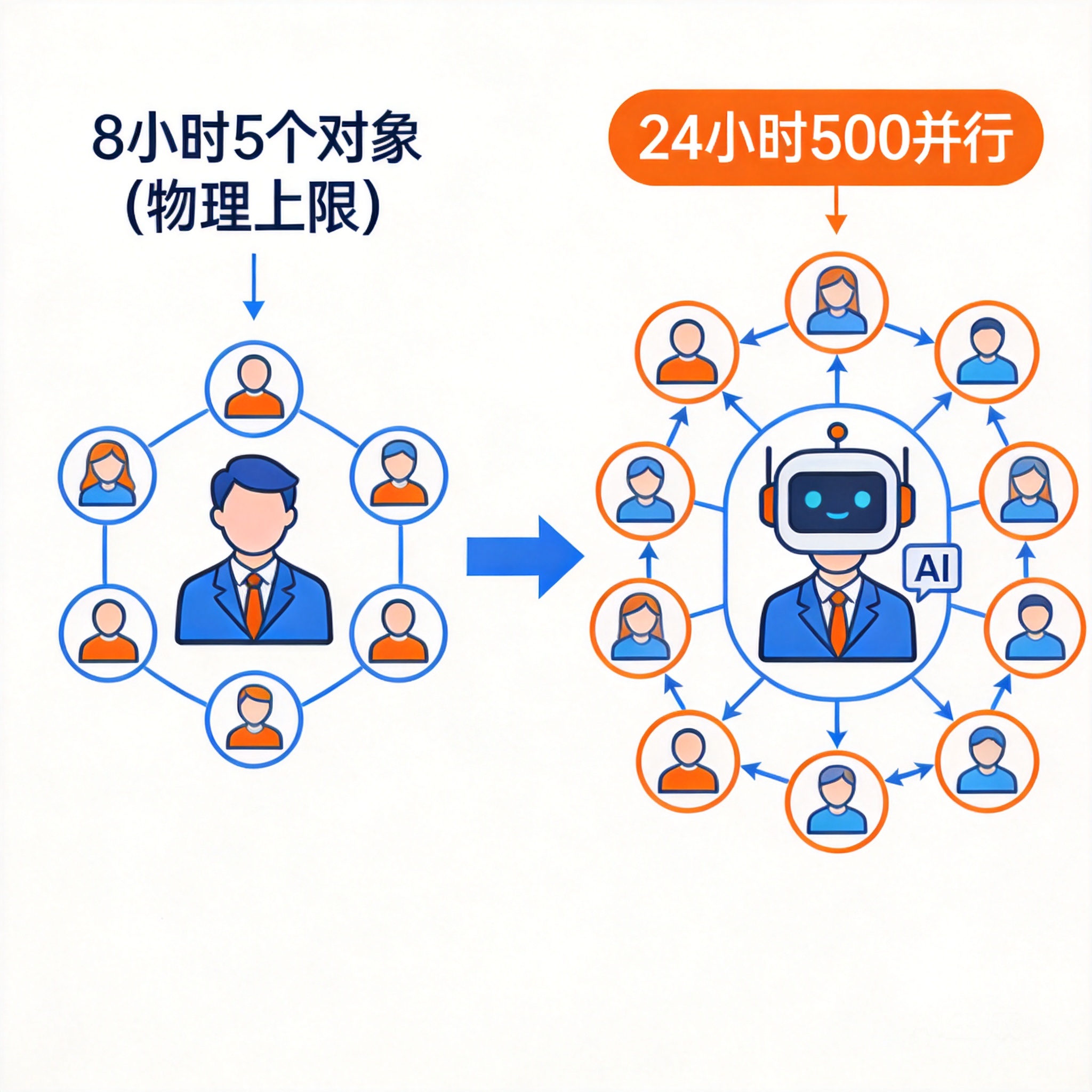
这件事人能做,但人有 8 小时和 5 个销售对象的物理上限;模型可以并行 500 个对象、24 小时。
替人重复做决策:金融分析、PR review、自动化运维
这是 2026 年最值得关注的新赛道,2024 年还没成气候。
Rogo 的描述是"evaluates frontier models for institutional finance"——它本身就是给机构金融做模型评估的,潜台词是机构金融已经在用模型做投资决策辅助。Delivery Hero 公布的数字最猛:Claude 帮他们的 agent 一天合并 100+ 个 PR。一天 100 个 PR review 决策是模型做出来的,不是人。
为什么 2026 年这条赛道才起来?因为前两年的模型在做决策时不够稳——一个金融分析错了直接亏钱、一个 PR merge 错了直接挂线上。要等到模型本身的稳定性 + 工具调用 + 人类审核闭环这三件事都成熟,企业才敢把决策权交出去。Anthropic 在 2026 年专门推了 Claude Managed Agents(Pendo 那个故事里写明了),就是为这条赛道服务。
写代码:单独成立的一条主赛道
我把它单拎出来,因为这条赛道大到撑得起一整套产品——OpusClip / Bolt / Bubble / Delivery Hero 全部在用 Claude Code 做生产级代码生成。Bolt 直接"基于 Claude Agent SDK 搭了 autonomous design system agent",Bubble 用 Claude 把"prompts 变成 production apps"。
OpenAI 那边自己披露的数字也夸张:2M+ 开发者在 OpenAI API 上构建,含 92%+ Fortune 500 公司(来源 a16z 2024 年报告,2026 年只会更高)。这意味着写代码这件事,现在已经不是"开发者用 AI 辅助",而是"代码本身大部分由 AI 写、开发者做 review 和编排"。
不太适合大模型 API 的场景:精确数值、强实时、极致低延迟
写到这反过来说一下,避免误导。
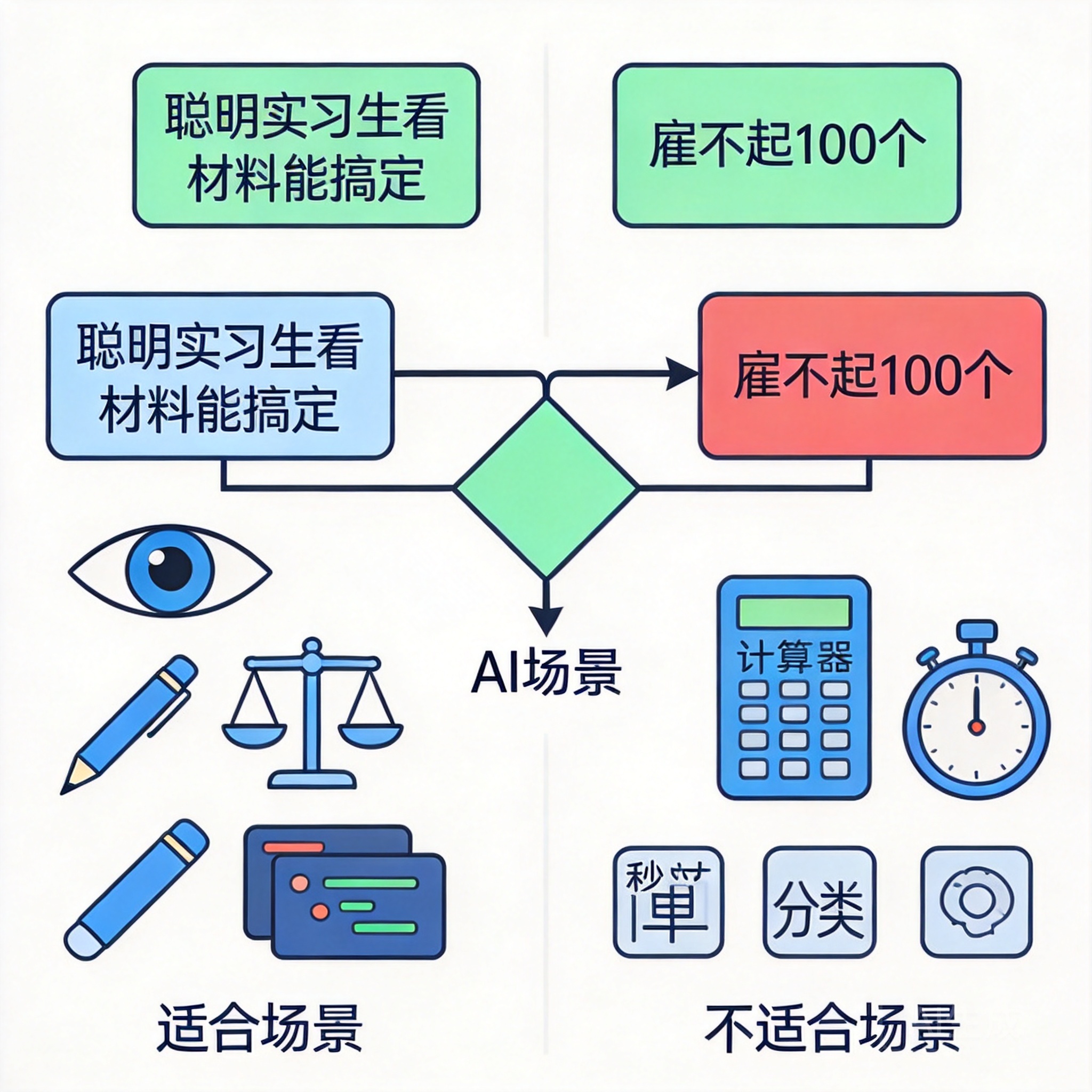
精确计算(财务对账、税务计算)不适合——大模型本质是概率模型,会算错小数点。这种场景应该走传统规则引擎,模型只做最外层的自然语言交互。
毫秒级实时决策(高频交易、自动驾驶感知层)不适合——模型推理延迟在 100ms-2s 量级,不可能赶得上。
输入输出极小的高频场景(每天百万次的简单分类)不适合——单纯算 token 成本,传统 NLP 模型便宜两个数量级。
判断标准其实只有一句话:如果你的业务里有"一个聪明实习生看完一堆背景材料能搞定,但你雇不起 100 个聪明实习生"的环节,那就是大模型 API 的场景。反之不是。
国内开发者落地这件事,有一个实际问题先解决
写到这里不可避免要提一句——Anthropic 的 supported regions 名单里没有中国大陆(这点我前几天专门写过一篇)。所以国内团队要做以上任何一类业务,第一步不是产品定义,是 API 接入路径。
主流做法是用兼容 OpenAI/Anthropic 双标准的国内中转网关,例如七牛云 AI 的 portal.qiniu.com/ai-inference/api-key 这类入口——SDK 一行不改,base_url 换一下就跑通,国内服务器直连,开发票走人民币。等你产品跑顺了再考虑要不要走 AWS Bedrock 海外账号那条更重的合规路径。
一个建议
如果你正在选场景,别看那些 “100 个 AI 应用方向” 的清单——那些清单在 2024 年看起来都对,到 2026 年大半已经死了。
更靠谱的做法是去 claude.com/customers 和 OpenAI 的 stories 页面挨个翻,只看那些已经公开姓名、敢上 logo、敢披露数字的案例。能上官网的客户至少证明了三件事:场景跑通了、ROI 算清楚了、模型厂商愿意把它当样板。剩下的"大模型可以做 X"的设想,可以参考但不要直接押注。
本文 17 个客户案例(Notion / Slack / Figma / HubSpot / Pendo / Vapi / Rogo / OpusClip / Reversia / Smartsheet / Artemis / Gradial / Bolt / Delivery Hero / AirOps / Bubble / Mutiny)来自 2026-05-15 抓取 claude.com/customers 页面所得。OpenAI “2M+ 开发者、92% Fortune 500” 数据引自 a16z《Top 100 Gen AI Consumer Apps》报告。Anthropic supported regions 现状基于 docs.anthropic.com 直查。
参考链接:
● Anthropic 官方客户故事:https://claude.com/customers
● a16z 生成式 AI 应用排行:https://a16z.com/100-gen-ai-apps/
