Loop Engineering 是什么?2026 年最热 AI 工程方法论完全解析
话题:AI Agent 工程 | 适用人群:开发者、AI 工程师、产品经理
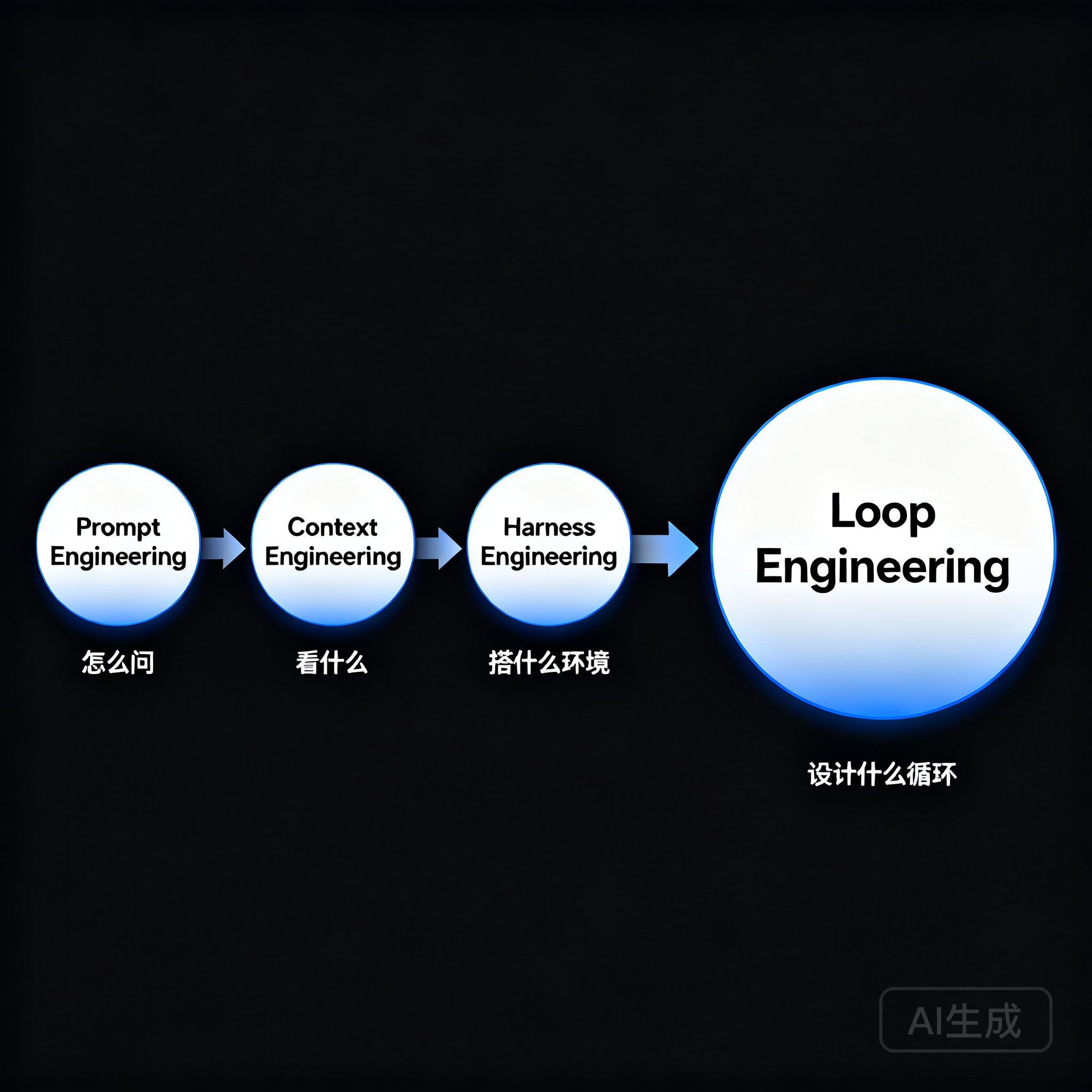
Loop Engineering(循环工程)是 2026 年 6 月由 OpenClaw 创始人 Peter Steinberger 在一条引发 800 万次浏览的推文中正式提出的 AI Agent 工程范式——其核心主张是:你不应该再给编程 Agent 写提示词,而应该设计一套能让 Agent 自主迭代的循环系统。继 Prompt Engineering、Context Engineering、Harness Engineering 之后,Loop Engineering 成为 AI 工程方法论的第四次范式跃迁,标志着人在 AI 工作流中的角色从"逐句指挥者"退化为"系统设计者"。五要素构成其骨架:明确目标、上下文管理、可调用工具、产出评估、停止标准;五者组合起来,Agent 从单次调用变为自我迭代、自我修正的闭环。本文系统拆解 Loop Engineering 的来龙去脉、核心结构与落地路径。
Loop Engineering 是什么?一句话定义
Loop Engineering,就是用你设计的系统来替代你自己去 prompt Agent。
传统做法是人写提示词、Agent 执行一次、人看结果再写下一条。Loop Engineering 把这个"人在中间传话"的模式彻底拆掉——你定义一个目标,系统自动完成"执行→观察→评估→修正→再执行"的闭合回路,Agent 在循环中持续迭代直到达成目标。
重点不在"自动",在闭环。一个定时跑任务的脚本不是 Loop Engineering;一个能感知自身输出质量、判断是否达标并决定下一步行动的 Agent 系统,才是。
四代工程方法论演进:Loop 从哪里来?
三年时间,AI 工程实践完成了四次清晰的范式跃迁:
四者不是替代关系,是层叠关系。用知乎上流传最广的比喻:“Prompt 是你怎么问他,Context 是你让他看见什么,Harness 是你把他放在什么环境里,Loop 是你让这个系统怎么自己转起来。”
Loop Engineering 的五大核心要素
一个完整的 Loop 系统由以下五要素构成(来源:东方财富网,2026-06-15):
1. 明确的目标(Goal)
不是模糊的"帮我优化代码",而是可验证的结果定义:测试通过率从 72% 提升到 95%、代码复杂度降低 30%。目标必须是 Agent 自己能判断是否达成的,而不依赖人的主观评估。
2. 上下文管理(Context Management)
Loop 中的上下文不是静态的,而是随迭代动态更新。每轮执行后,哪些信息需要保留、哪些需要压缩、哪些需要遗忘——这套策略决定了 Agent 在长循环中是否越跑越准还是越跑越乱。
3. 可调用的工具(Tool Access)
Agent 在循环中需要调用真实工具:运行测试、读写文件、搜索代码库、调用外部 API。工具链的完整性和权限边界,直接决定 Agent 能解决的问题边界。Claude Code 和 Codex CLI 当前均已具备完整工具调用能力,是构建 Loop 的主流宿主。
4. 对产出的评估(Output Evaluation)
这是 Loop Engineering 与简单循环脚本的本质区别。评估可以是:运行单元测试(客观)、调用另一个 LLM 打分(主观)、对比 diff 判断变更范围(混合)。没有评估机制,循环只会无限执行,无法收敛。
5. 停止标准(Termination Condition)
目标达成时停止,或达到最大迭代次数时优雅退出。停止标准的设计直接影响 Token 消耗和结果质量的平衡——这也是反对者质疑"Loop 会无限烧 Token"的核心争议点。
Loop 的运行机制:目标→执行→观察→评估→修正
一个 Loop 的单次迭代过程如下:
定义目标
↓
Agent 制定执行计划
↓
调用工具执行(写代码、运行测试、读文件…)
↓
观察执行结果
↓
评估:是否达到目标?
├── 是 → 输出结果,退出循环
└── 否 → 分析差距,修正计划 → 返回执行
这个结构与传统编程中的 while 循环在形式上类似,但本质不同:传统 while 循环执行的是确定性指令序列,Agent Loop 执行的是目标导向的推理序列——每次迭代的具体行动由 Agent 根据上下文自主决策,不是预先写死的。
Loop Engineering 和 Harness Engineering 的区别
这是最常见的混淆点:
简单说:Harness 是舞台,Loop 是剧本。搭好舞台之后,Loop 决定演员(Agent)如何自主把戏演完。
怎么用 Claude Code 实现一个最简 Loop?
以"自动修复单元测试直到全部通过"为例,在 Claude Code 中一个最简 Loop 的实现思路:
# 在 CLAUDE.md 或系统提示中定义 Loop 目标与停止条件
# 目标:让所有测试通过(npm test exit code = 0)
# 最大迭代次数:10 次
# Claude Code 执行时会自主循环:
# 1. 运行测试 → 读取失败信息
# 2. 定位错误代码 → 修改
# 3. 再次运行测试 → 判断是否通过
# 4. 未通过则继续下一轮,超过 10 次则输出当前进度并退出
Claude Code 的 Hooks 功能(PostToolUse、Stop 等事件钩子)天然适配 Loop Engineering 的评估和停止机制——可以在每次工具调用后注入评估逻辑,在达到停止条件时中断循环。
七牛云 Claude Code 配置指南提供了接入统一推理后端的完整步骤,支持在 Loop 执行中按任务复杂度动态切换模型,降低长循环的 Token 成本。
Loop Engineering 适合哪些场景?
争议:Loop Engineering 真的是新概念吗?
Peter 的推文在 X 引发了激烈争论,主要质疑有两点:
质疑一:“Loop 会无限烧 Token”
这是真实风险。设计不当的 Loop(缺乏有效停止条件)确实可能陷入无限循环。这是实现质量问题,不是范式本身的缺陷——就像写了死循环不是"for 循环"这个概念的错。有效的 Token 成本控制需要在停止条件中引入预算约束。质疑二:“这只是旧概念换新词”
从技术角度,ReAct、MCTS 等框架早已实现类似机制。Loop Engineering 的贡献不在技术创新,而在于把原本散落在学术论文和框架文档里的实践,统一成一个工程师可以操作的心智模型。
常见问题 FAQ
Q1:Loop Engineering 会取代 Prompt Engineering 吗?
不会取代,是升级。写好提示词仍然是设计 Loop 的基础能力——目标定义、评估标准、停止条件,本质上还是在写给 Agent 看的"提示词",只是组织方式从线性变成了闭环。Q2:没有编程基础能实践 Loop Engineering 吗?
目前门槛较高。设计有效的评估函数和停止条件需要对 Agent 工作机制有基本理解。随着 Claude Code、Codex 等工具进一步封装 Loop 能力,未来门槛会降低。Q3:Loop Engineering 和 Multi-Agent 是什么关系?
Multi-Agent 是 Loop 的一种扩展形式——多个 Agent 各自负责 Loop 中的不同环节(一个执行、一个评估、一个修正)。单 Agent Loop 是入门形态,Multi-Agent Loop 是生产级形态。Q4:已经有哪些公司在实践 Loop Engineering?
根据东方财富网报道(2026-06-15),已有企业在生产环境中跑了近 3000 个 Agent Loop,主要应用于代码审查、文档生成和数据处理流水线。Q5:如何评估一个 Loop 设计的质量?
三个指标:收敛速度(平均多少轮达到目标)、Token 效率(达成目标消耗的 Token 数)、鲁棒性(在异常输入下是否能优雅退出而非死循环)。
小结
Loop Engineering 不是凭空出现的炒作词,而是 AI Agent 从"工具"走向"自主系统"这一趋势在工程实践层面的自然命名。Peter Steinberger 的那条推文之所以引发 800 万次浏览,恰恰说明行业早已在实践这套模式,只是缺少一个统一的叫法。五要素(目标、上下文、工具、评估、停止)是目前最清晰的实践框架;Claude Code 和 Codex CLI 是当前最成熟的宿主工具;Token 成本控制和停止条件设计是落地时最需要认真对待的工程问题。本文数据截至 2026 年 6 月,相关工具和定义仍在快速演进,建议持续关注各工具官方文档。
