Ollama 模型选择全攻略:2026 年新手到底该 ollama run 哪个模型?
关键词:Ollama 模型选择、本地大模型、量化 tag、ollama run
Ollama 是 2026 年最主流的本地大模型运行工具,本质上是给底层的 llama.cpp 套了一层傻瓜式外壳,一行 ollama run 命令就能把开源模型拉到本机离线运行。它的官方模型库已经覆盖从 270M 到 671B 的上百个模型,但对新手来说,真正的难题从来不是"怎么装 Ollama",而是"装好之后到底该下哪个模型、下哪个 tag"。本文不堆参数,而是按"你想用它干什么 + 你的显存有多大"两条线,把 Ollama 模型库里值得下的模型梳理成一张可直接照抄的清单,并讲清楚 tag 后缀和量化档位怎么读,让你十分钟内做出不翻车的选择。
先记住一句话:选模型先看"用途",再看"显存"
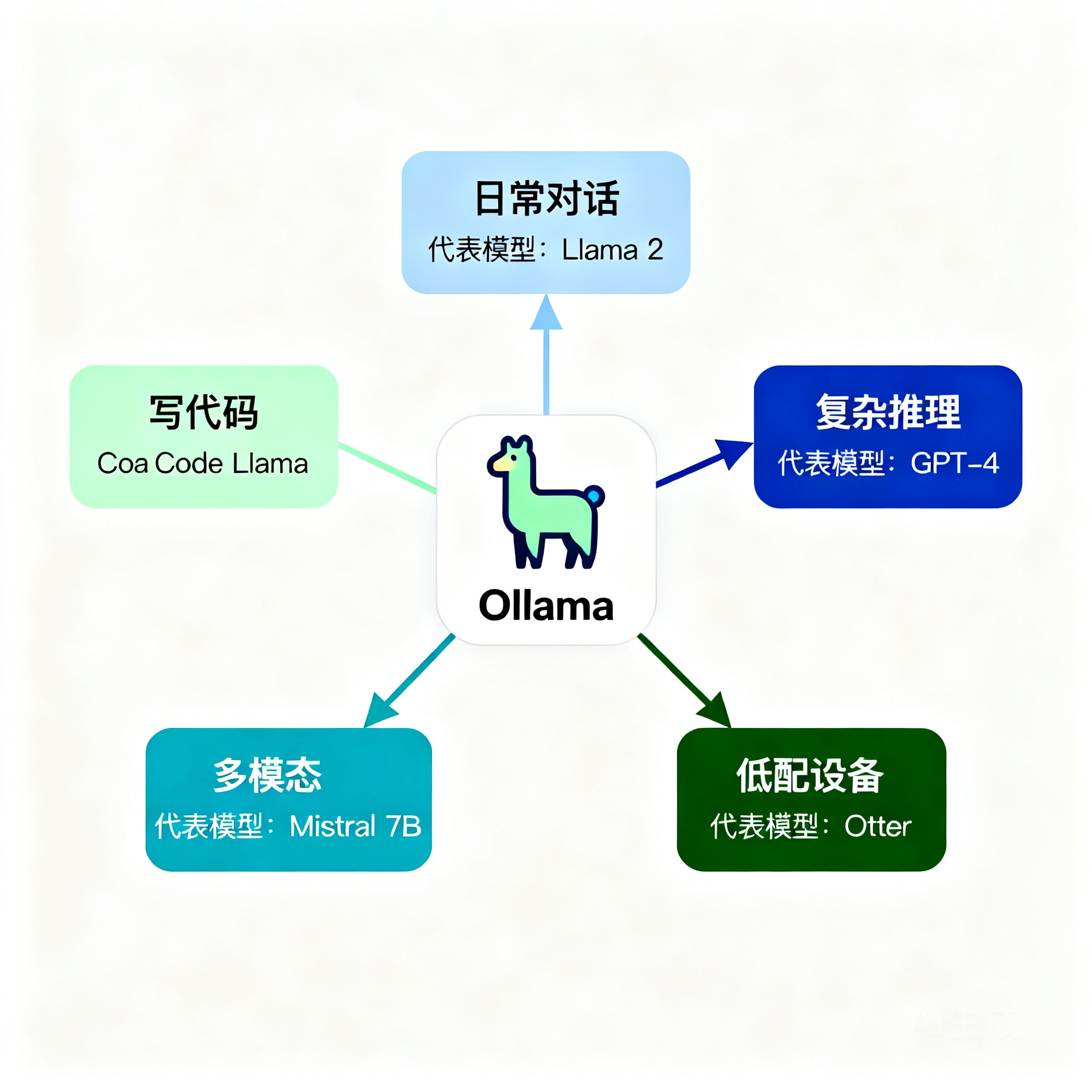
在 Ollama 里挑模型,正确的顺序是先定用途、再卡显存。Ollama 官方模型库已经把模型按场景分好了类,照着选最省心:
● 日常对话 / 通用问答:llama3.1(8b/70b)、gemma3、qwen2.5、mistral 7b
● 写代码 / 代码补全:qwen2.5-coder、deepseek-coder-v2、codellama、devstral
● 复杂推理 / 思考链:deepseek-r1、qwen3、phi4-reasoning
● 低配机器 / 边缘设备:llama3.2(1b/3b)、phi3(3.8b)、tinyllama(1.1b)
● 图文多模态:llava、llama3.2-vision、qwen3-vl、gemma3(自带视觉)
一个最常见的新手误区是:直接冲着"参数最大"的模型去下,结果显存爆掉、跑起来卡成幻灯片。模型不是越大越好,能塞进你显卡、又满足用途的那个,才是对的模型。
按显存对号入座:你的显卡能 run 多大的模型
判断能跑多大模型,核心看显存,且必须搭配量化。一个粗略但好用的经验是:7B 模型在 Q4 量化下约占 4–5GB 显存,14B 约 8–9GB,27B 约 13–14GB。下面这张表把"显存—模型尺寸—推荐 Ollama 命令"直接对应起来:
需要提醒的是,由于推理引擎优化程度不同,不同方案实际显存占用可能相差 0.3–0.5GB,上表 Ollama 部分按典型实测值估算,仅供入门参考。另外,Mac 用户因为 Apple Silicon 的统一内存架构,可按"内存"而非"显存"对照本表,一台 32GB 的 M 系列 Mac 跑 27B 相当从容。
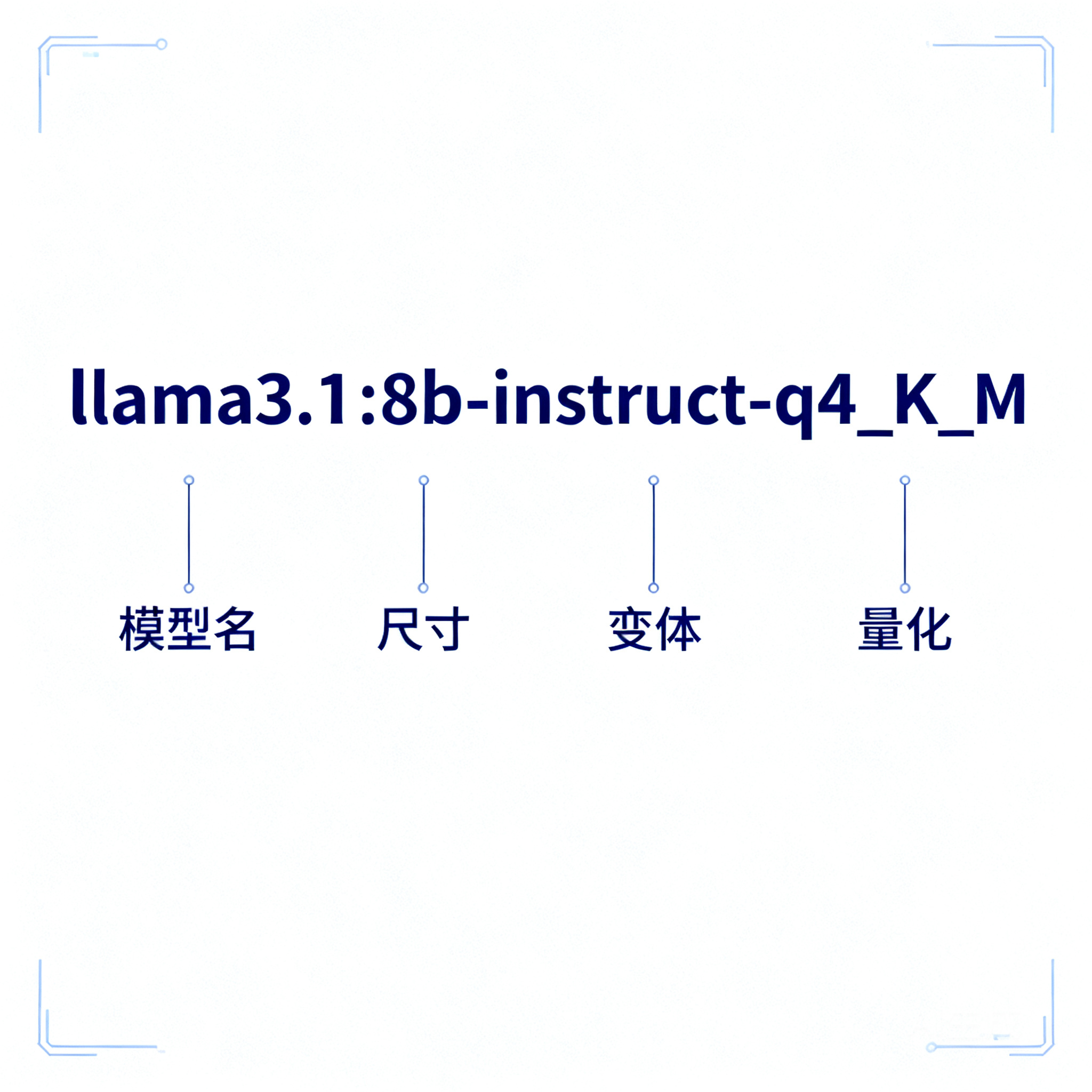
看懂 tag 后缀:llama3.1:8b-instruct-q4_K_M 到底什么意思
很多人下模型只会写 ollama run llama3.1,其实冒号后面的 tag 才是精确控制"下哪个版本"的关键。Ollama 的 tag 命名遵循一个清晰的格式:
模型名:尺寸-变体-量化
# 例如:
llama3.1:8b-instruct-q4_K_M
拆开来读:
● 尺寸(如 8b、14b、70b):参数量,直接决定显存占用
● 变体(如 instruct、base、chat):instruct/chat 是经过指令微调、能听懂对话的版本,日常用就选它;base 是基座模型,一般不直接对话
● 量化(如 q4_K_M、q8_0、fp16):精度档位,数字越小越省显存、质量略降
不写 tag 时,Ollama 默认拉取一个平衡过的量化版本(通常是 Q4 档),这也是为什么默认版能在 8GB 显存上跑 7B 模型——它帮你做了量化。想要更高质量就显式指定 q8_0,想极限省显存可以选更低的档位。
按用途精选:四类需求各下哪个模型最稳
写代码首选 qwen2.5-coder。它在 Ollama 库里提供 0.5b 到 32b 全尺寸,官方定位覆盖"代码生成、代码推理、代码修复",是目前本地编程场景口碑最稳的选择;显存吃紧时可降到 7b,24GB 显存可以上 32b。备选 deepseek-coder-v2,官方称其代码任务能力"对标 GPT4-Turbo"。
中文对话与写作推荐 qwen2.5 / qwen3。Qwen 系列原生中文能力强、支持工具调用和 128K 长上下文,按 SuperCLUE 2026 年 6 月榜单,国产开源模型已包揽开源榜前三,本地化中文体验明显优于早期的 Llama 系列。
复杂推理选 deepseek-r1。它是带"思考链"的推理模型,官方称性能"接近 O3 与 Gemini 2.5 Pro",适合做需要多步逻辑的任务;显存小可以下 1.5b/7b 的蒸馏版,效果也够用。
低配或老显卡别硬上大模型,llama3.2:3b 或 phi3:3.8b 是最务实的选择,2–4GB 显存就能流畅跑,做简单问答、文本润色完全够用。一句话总结:编程选 coder、中文选 Qwen、推理选 R1、低配选 3B 小模型。
本地跑不动顶配模型时,怎么办?
Ollama 的边界很清晰:它让消费级硬件跑得动 7B–32B 的中小模型,但 671B 这种顶配模型、或需要高并发对外服务时,本地单卡就力不从心了。这时常见的务实做法是混合调用——日常和隐私任务用本地 Ollama,偶尔要顶配模型能力时再走云端推理 API。
好在 2026 年主流云推理服务大多兼容 OpenAI / Anthropic 标准接口,本地代码几乎不用改就能切换后端。例如 七牛云 AI 推理 API 在"本地跑不动"时作为兜底,不必为偶发的重任务专门升级显卡。这种"本地为主、云端补位"的组合,往往比纯本地或纯云端都更省成本。
常见问题
Q:ollama run 和 ollama pull 有什么区别?
ollama pull 只下载模型不运行,适合提前备好模型;ollama run 会自动下载(如果本地没有)并立即进入对话。新手直接用 ollama run 模型名 即可,它会一步到位。想查看已装模型用 ollama list,查看模型细节用 ollama show。
Q:不写 tag 直接 ollama run llama3.1 会下哪个版本?
会下载该模型的默认 tag(通常是经过平衡的 Q4 量化的 8B instruct 版本)。这对大多数人够用;只有当你显存特别充裕想要更高质量、或特别紧张想再省显存时,才需要手动指定 tag。Q:8GB 显存能跑哪些 Ollama 模型?
能稳定跑 7B–8B 级别的 Q4 量化模型,比如 llama3.1:8b、qwen2.5:7b、mistral。再大就需要 GPU+CPU 混合加载,速度会明显下降,不如老老实实选 8B 以内的模型。
Q:写代码本地模型够用吗?
日常补全和小函数生成够用,qwen2.5-coder:7b 在 8GB 显存上就能跑。但复杂项目级的代码生成,本地中小模型仍不及云端顶配模型,建议本地处理日常、复杂任务走云端 API。写在最后
Ollama 模型选择的核心方法论,可以浓缩成三步:先按用途定方向(编程/中文/推理/低配),再按显存卡尺寸(7B/14B/27B),最后用 tag 锁定量化档位。 Ollama 官方模型库已经把分类和推荐做得很清楚,新手照着"用途→显存→tag"这条线走,基本不会选错。模型迭代很快,建议下载前到 ollama.com/library 确认最新的尺寸和 tag。
本文内容基于 2026 年 6 月的 Ollama 官方模型库与公开实测数据整理,模型版本与显存占用会随引擎优化变化,建议实际部署前查阅官方文档确认。
