
FlashMLA突破H800计算上限加速DeepSeek推理
上周五,DeepSeek 重磅预告了本周将是 OpenSourceWeek。今天上午,开源周第一弹已经来了——FlashMLA,针对 Hopper GPU 优化的高效 MLA 解码内核,支持变长序列处理。消息一经发布就引爆了开源社区,好评如潮,目前 GitHub 页面的 Star 星数已经超过 5k。
众所周知,MLA 是一种创新注意力架构,也是 DeepSeek 系列模型的基本架构,旨在优化 Transformer 模型的推理效率与内存使用,同时保持模型性能。FlashMLA 通过优化 MLA 解码和分页 KV 缓存,能够提高大语言模型的推理效率,尤其是可以在 H100 / H800 这样的高端 GPU 上发挥出极致性能。按照官方说法,使用 FlashMLA 使用之后,可让 H800 在内存受限场景下达到 3000GB/s 带宽利用率,在计算受限场景下达到 580TFLOPS 算力利用率。
让我们详细看一看这个开源项目的核心内容。
目前已发布:
BF16 计算精度支持
分页式 KV 缓存管理(块大小64)
快速启动
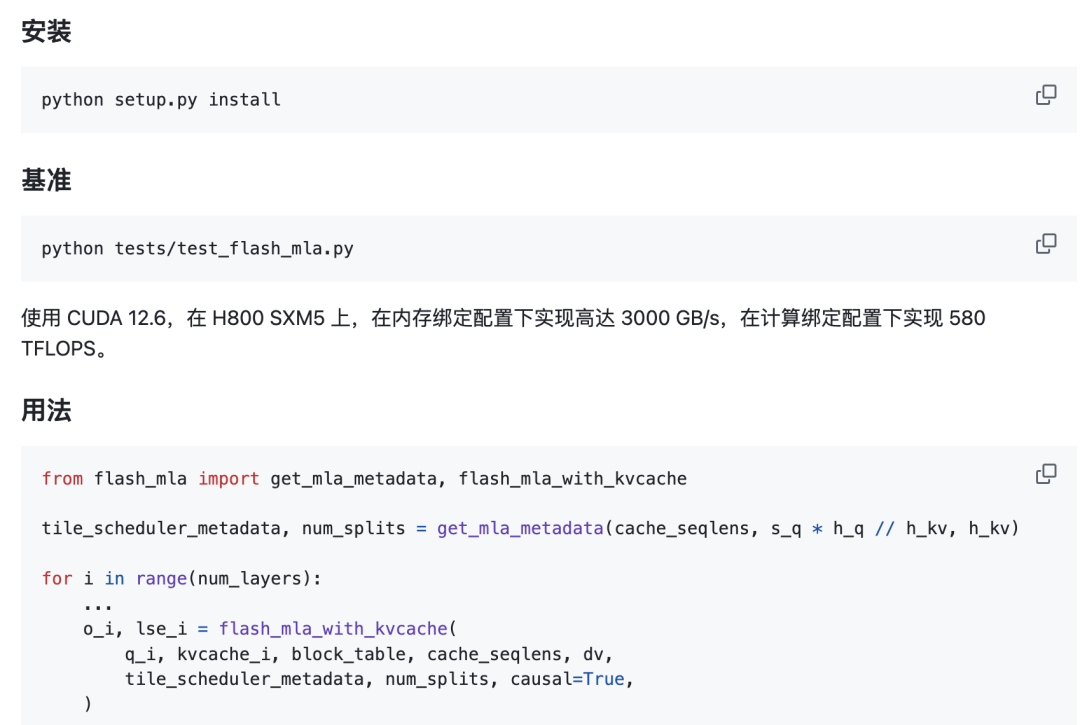
要求
Hopper GPU
CUDA 12.3 及以上版本
PyTorch 2.0 及以上版本
注1:MLA 指代 Multi-head Linear Attention(多头潜注意力机制);
注2:KV缓存采用分页式内存管理,支持动态序列长度;
注3:性能数据基于标准测试环境,实际表现可能因硬件配置和工作负载特征有所波动;
FlashMLA 的发布揭示了 AI 行业的两大趋势——首先是软硬件协同优化,通过技术创新,释放算力潜能的趋势;其次是开源社区普惠 AI 民主化,极大便利个人与企业私有化部署的趋势。
作为开源模型,DeepSeek-R1 效果比肩海外巨头的闭源模型,在推理效率、场景适配等多个维度上树立了新的标杆。此前,七牛云已经推出了满血版的 DeepSeek-R1 671b 全参模型和 DeepSeek-R1 蒸馏版模型,并支持一键部署到 GPU 云主机。现在,无需等待,点击阅读原文,即可享受 GPU 云服务器超值优惠!
「特别提醒」H100 / H800 部署请扫码添加人工客服企业微信详细洽谈。

