
Go+ v1.3:Go+ Mini Spec、领域文本及 TPL
在《2024 收官篇:Go+ 已具备第一的潜力》一文中我们提到,2024 年 Go+ 的关键进展从长远来看都至关重要。它们分别是:
Go+ classfile 语法转正(Go+ v1.2 版本)
引入 Go+ Mini Spec(Go+ v1.3 预览版)
支持 import C/C++ 和 Python 库(Go+ v1.3 预览版)
今天 Go+ v1.3 版本功能已经进入冻结状态。除了还在进行中的 Wasm 支持,不会再增加任何功能。所以,这一篇我们打算对 Go+ v1.3 的重要更新进行说明,并对其中 Go+ Mini Spec、领域文本及 TPL 相关的内容进行详细展开。
Go+ 语言增强的逻辑边界
不过在介绍 Go+ v1.3 的更新之前,我想先说说 Go+ 语言增强的逻辑边界。我希望能够讲明白的是,什么样的功能可能会被加入 Go+,而什么样的功能不会被加入。
首先,我们希望 Go+ 语言的涉及的概念尽可能少,并通过 Go+ Mini Spec 输出语言的最佳实践,它大体只涉及:
对象:字面量、常量、变量、包(package)
函数:运算符(operator)、函数、闭包、方法
流程控制:if/else、switch/case、for/break
类型:基础类型、列表、字典、结构体(不含方法)
类文件:变量+函数构成用户自定义的类(面向对象的简化)
什么样的语法是 Go+ 会考虑增加的?
能够降低 Go 语言使用门槛的。例如 Go 语言的列表添加元素
a = append(a, v1, v2, ..., vN)非常不利于新人理解。比较理想的语法是a.append(v1, v2, ..., vN),但限于语言的基础设定(切片是值而不是指针)而无法做到,所以它最终演变成a <- v1, v2, ..., vN。丰富的对象。世界之大,无奇不有,物种(对象)可以有很多。计算机最基础的职能就是对各类对象进行计算(运算),它不会带来理解上的负担。所以只要符合人类直觉,被广泛采纳的对象,Go+ 就能够接受加入它。例如 Go+ v1.3 增加的:带单位的数值字面量(
1s表示1秒)、领域文本。丰富的函数。函数太多不会带来理解上的负担(就像这个世界上人名很多一样)。运算符(operator)也是函数。所以 Go+ 支持的运算符非常多(例如它提供了
->、<>运算符),builtin 函数的规模也远大于 Go 语言。Go+ 可以说是最在意领域友好(SDF,Specific Domain Friendly)程度的语言,只要某种运算符在某个领域被广泛接纳,Go+ 可以几乎无负担地为其增加新运算符。
不在降低 Go 语言使用门槛、丰富的对象、丰富的函数这三大点覆盖范围的语法,Go+ 几乎不太可能会加入(除非有证据表明该语法已经通过多种语言验证过获得了广泛共识,并且也的确非常易于理解和掌握)。
Go+ v1.3 重要更新
理解了 Go+ 语言增强的逻辑后,我们将 Go+ v1.3 重要更新分为文档、语言特性、内置函数和标准库四大类进行说明。
文档
完善 Go+ Mini Spec 文档。Go+ Mini Spec 是一个经过精心设计的语言规范,它是 Go+ 语言的精髓:提供一个最小但图灵完备的语法集合,同时亦代表 Go+ 编程的最佳实践。
自动生成的 Go+ builtin 函数文档。Go+ 的 builtin(内建)函数的规模远大于 Go 语言,这使得它简化了最常见任务的表达。并且,Go+ 的基础类型也有方法,例如
string类型有内建常见的字符串操作。其中"123".int将字符串转为整数类型;"get_table_name".split("_")分割字符串得到列表["get", "table", "name"]。
语言特性
告别 append,列表添加元素的新语法:<- 运算符。Go 程序员熟悉的
a = append(a, v1, v2, ..., vN)现在变成了a <- v1, v2, ..., vN这种更直观的语法。连接两个列表也一样:以前用a = append(a, b...),现在变成了a <- b...。引入
for .. in替代之前的for .. <-,和主流语言更加一致。旧的for .. <-仍将支持,但是在使用 gop fmt 格式化代码之后会自动将<-转为in。引入带单位的数值字面量,比如
1s表示 1 秒。这样我们可以用wait 0.5s来取代以前冗长的wait 0.5*time.Second写法,语义也更为直观。值得注意的是,带单位的数值常量的含义因数据的类型而异。例如wait 1m因为参数是时间类型,所以这里1m的含义是 1 分钟。而step 1m的参数类型是距离,所以这里1m的含义是 1 米。支持用户自己选择 Go 编译器,并可在 go.mod 中指定使用哪个 Go 编译器。Go+ 现在支持的 Go 编译器主要是:
go(Go 官方的编译器)、llgo(Go+ 团队维护的 Go 编译器)、tinygo(专为嵌入式环境而生的 Go 编译器)。当前 Go+ 默认使用go,未来会默认使用llgo。初始化一个使用llgo的模块只需要执行gop mod init -llgo mymodule命令即可。支持 import C/C++ 和 Python 库。Go+ 对 import C/C++ 和 Python 库的支持通过 LLGo 完成。当前 C/C++ 库的支持已经非常成熟,并且我们将会提供自动化工具覆盖主流的 C/C++ 库,而不必像 cgo 那样需要用户自己手工迁移 C/C++ 库到 Go 世界。Go+ 对 Python 库的支持仍然是实验性的,它将是 Go+ 未来版本的重点。
Wasm 支持。Go+ 对 Wasm 的支持通过 LLGo 完成。LLGo 生成的 Wasm 将比 Go 官方编译器编译得到的 Wasm 尺寸更小,且在使用 cgo 的情况下仍然支持生成 Wasm 文件(Go 官方编译器在使用 cgo 下不支持 Wasm)。
classfile 内置 clone 支持,使对象克隆操作变得更加高效。可能的应用场景:Web 框架中为每个新连接创建 Handler 实例。在没有 clone 支持前,我们通常需要通过 reflect(反射)机制来实现对象的 clone,这不仅代码晦涩难懂,而且会带来不小的性能开销。
增加了领域文本(Domain Text Literal)支持。详细下文解释。
内置函数
增加内置函数
type,作为reflect.TypeOf的替代,用于查看一个对象的类型。string 和 []string 类型增加 Capitalize 方法,用于将一个字符串的首字母转为大写。例如:
"hello".capitalize会得到字符串"Hello",["hello", "world", "!"].capitalize会得到["Hello", "World", "!"]。把 C 风格的变量x := "get_table_name"改为驼峰风格的"GetTableName"只需要x.split("_").capitalize.join("")。
标准库
新增了标准库
gop/tpl,它类似yacc和bison,提供了类 EBNF 文法以理解并处理特定领域的文本。但它不是一个独立的工具,而是内嵌在 Go+ 语言中的领域文本。详细下文解释。
Go+ Mini Spec
前面我们已经提到,Go+ Mini Spec 是一个经过精心设计的语言规范,它是 Go+ 语言的精髓:提供一个最小但图灵完备的语法集合,同时亦代表 Go+ 编程的最佳实践。
所以整理 Go+ Mini Spec 规范文档,是一份非常重要而且严肃的事情。
这份工作复杂而艰巨。它开始于 2024 年 9 月发布的 Go+ v1.3 预览版,到现在虽然完成了最难的部分,但仍然还没有完全完成。
出于工程严谨性的考虑,对一篇这么长但是又非常重要的 Paper Work,我的第一个思考是,有什么办法证明我写的东西是没有错漏的,它能不能像代码一样可以被验证。
这其实是 Go+ v1.3 版本增加 TPL 文法支持的起因。
有了 TPL 文法,Go+ Mini Spec 就不只是文档,它也成了一段基于 TPL 文法描述的代码:
https://github.com/goplus/gop/blob/v1.3.8/doc/spec/mini/mini.gop#L28
这是 TPL 文法版本的 Go+ Mini Spec 大体的样子:
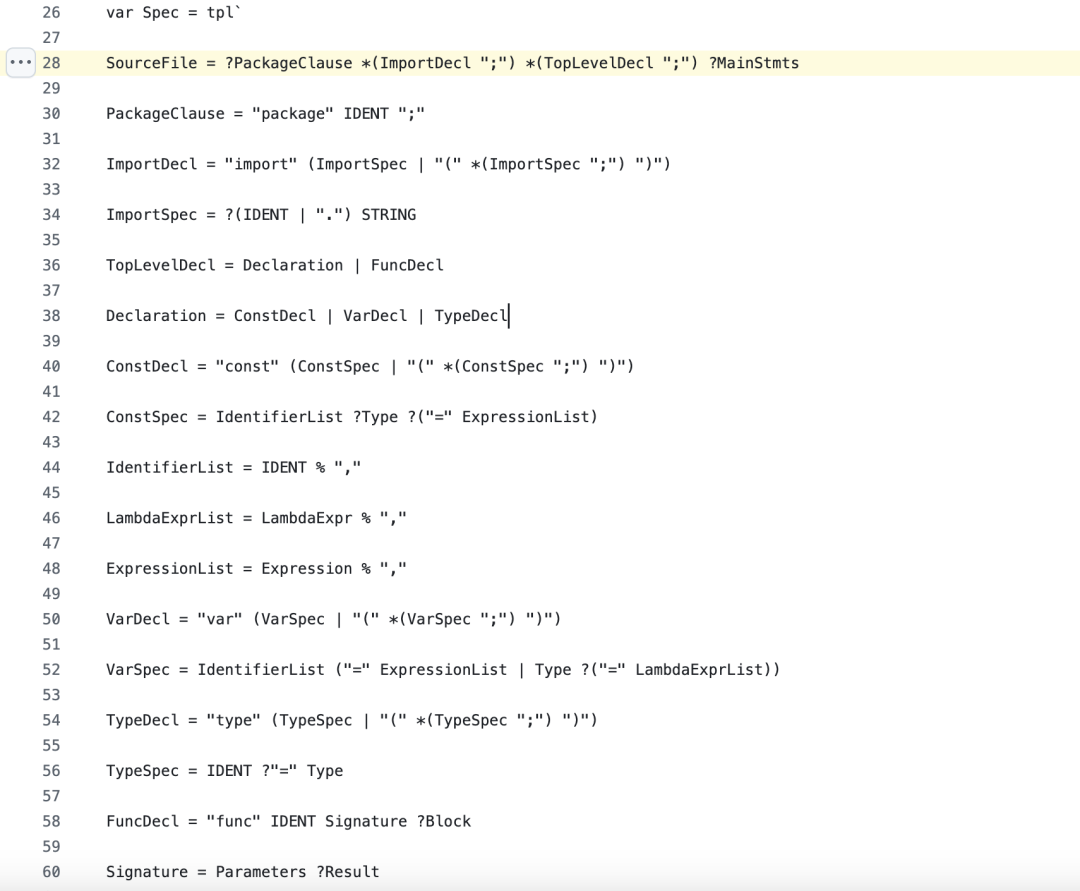
并且我们还提供了 gopminispec 程序来检验某个 Go+ 工程是否满足 Go+ Mini Spec:
https://github.com/goplus/gop/tree/v1.3.8/cmd/chore/gopminispec
我们还把 Go+ demo 分成了满足 Go+ Mini Spec 的,和使用了 Go+ Full Spec 扩展语法的这两类。将所有 Full Spec 的例子放到了 fullspec 子目录下:
https://github.com/goplus/gop/tree/v1.3.8/demo/fullspec
非 fullspec 子目录下的 demo 都已通过了 gopminispec 程序的检查。
有了 TPL 文法描述的 Go+ Mini Spec,后续 Go+ Mini Spec 规范文档的严谨性就得到了保证,我们将在 v1.3 版本最后阶段完成它的所有剩余工作。
领域文本(Domain Text Literal)
和领域文本相关的第一个提案(proposal),是 2024 年初有人提出希望 Go+ 支持 jsx 文法:https://github.com/goplus/gop/issues/1770
jsx 文法在前端开发中已经被广泛地应用。但对 Go+ 来说,内建 jsx 文法的收益并不明确,所以该提案一直被搁置。
直到由于 Go+ Mini Spec 的需要,我们需要在 Go+ 中支持 TPL 文法,于是这两件事情被放在一起来看。
在《2024 收官篇:Go+ 已具备第一的潜力》一文中我们提到,领域专用语言(DSL)不是一个好方向,大部分 DSL 都打不过通用语言。
但是和这个结论似乎背离的事实是,领域语言其实还是不少,只是没有出现在语言榜上:
界面描述:html、jsx
配置与通用数据表示:json、yaml、csv
文本语法表示:类 EBNF 文法 (包括 TPL 文法)、regexp(正则表达式)
办公文档:markdown、docx(微软 word 的最新格式)、html
这些领域语言的特点是,它们并不是图灵完备的。我对图灵完备的定义是:要有 io 能力(进而能够操作计算机各类外部设备)、可自定义函数、有常见流程控制能力。
它们和通用语言通常是良好协同关系,而非彼此取代。主流的通用语言通常都官方或通过社区实现了这些领域语言相关的库,以实现与这些领域语言的协同。
基于此,我没有以领域专用语言(DSL)来称呼它们,而是称之为领域文本(Domain Text Literal)。
Go+ 应该如何支持领域文本?
其实在有人提出希望 Go+ 支持 jsx 文法之后,我就在反复琢磨这个问题。最后我在 markdown 文档中找到了答案:

最初,我想干脆 Go+ 的领域文本和 markdown 的领域文本语法完全一致。但是考虑到这将导致 Go+ 代码将无法再作为领域文本嵌入到 markdown 文档中,这会极大降低 Go+ 与 markdown 之间的友好性,反复斟酌后最终选择了当前的 Go+ 领域文本表示(见上图)。
当前 Go+ 已经内置支持的领域文本有:
tpl
json, xml, csv
regexp, regexposix(和 regexp 类似,只是语法略有差异)
html(需要用户 import "golang.org/x/net/html" 才能使用)
以下是它们的一些例子:

用户完全可以自己添加新的领域文本的支持。所谓 domainTag 其实代表的是一个包(package),只要该 package 全局有 func New(string) 函数(该函数的返回值可以任意)即可。而领域文本其实就只是对该包的 New 函数的调用而已,因此原理非常非常简单。
但领域文本的意义并非只是少打几个字那么简单。
有了领域文本,Go+ 语言相关的工具链就可以理解它的语义,而不再只是作为普通字符串。这使得以下这些事情成为可能:
Go+ 的代码格式化(gop fmt)在格式化 Go+ 代码的同时,可同时对自己支持的领域文本也进行格式化。
Go+ 的 IDE 插件,可对自己能够理解的领域文本进行语法高亮,以及提供各种高阶的功能。
TPL(Text Processing Langugage)
TPL 是一门类 EBNF 文法的语言,你可以简单把它看作增强版的正则表达式库,可用于处理各类文本内容。相比正则表达式,它既强大,又直观(正则表达式以难阅读而闻名)。
TPL 最早诞生于 2006 年,并于 2008 年中开源。它是一个 C++ 模版库,类似于 boost spirit, boost xpressive:
https://code.google.com/archive/p/libtpl/
2015 年底我将其迁移到 Go 语言(并于 2016 年 3 月开源)https://github.com/qiniu/text
这次的迁移纯粹是因为我在 ECUG 大会的演讲需要有一个议题。于是我迁移了 TPL,并用它做了一门玩具性质的语言,叫 qlang:https://github.com/xushiwei/qlang
今年 3 月份,出于 Go+ Mini Spec 的需要,我决定将 TPL 迁移到 Go+。
这次迁移并不是简单将 Go 语言版本的 TPL 搬到 Go+。因为 Go+ 兼容 Go,所以 github.com/qiniu/text/tpl 这个包在 Go+ 本来就是可以直接使用的,不需要有专门的迁移动作。
所以 Go+ TPL 是对 TPL 的一次大重构。为什么要重构?
因为无论是 C++ 版 TPL 还是 Go 版本的 TPL,概念都有点多(上图是 C++ 版 TPL 相关的概念,Go 版本完全类似),不容易理解。究其原因,大部分是由于 TPL 有 Action 这样一个东西导致的复杂性。
所谓 Action,是指在规则匹配成功后执行的一个动作。因为 Action 有副作用,所以 C++ TPL 和 Go TPL 写代码心智负担略重。为了减轻负担,TPL 里面有一个 Mark 的概念,你可以简单理解它为无副作用的一类 Action。但 Mark 并不通用,仅仅是对 Action 副作用的一个小补丁。
Go+ TPL 决定放弃 Action,改为引入 “匹配结果改写(rewrite matching results)”。当规则当前匹配成功但是到后面发现整个分支都是错的时候放弃时,改写的匹配结果和规则是一起放弃的,这就解决了有代码带来的灵活性,但是又没有 Action 副作用带来的负担。
“匹配结果改写(rewrite matching results)”概念大大简化了 TPL 的复杂性。不过它并非 Go+ TPL 首创,而是源于我另一个名为 BPL(Binary Processing Library)的项目(它诞生于 2016 年 4 月,并于 2019 年开源):
https://github.com/goplus/bpl
理解 Go+ TPL,你只需要理解以下 3 件事情:
其一,命名规则:name = rule。整个 TPL 文法由一系列的命名规则构成,其中第一个命名规则叫根规则。rule 可以是以下规则的组合:
词,最基础的语法单元:如
INT,FLOAT,CHAR,STRING,IDENT,"+","++","+=","<<="等。关键字(
"keyword"):将一个IDENT用 "" 括起来,就成了关键字,例如"if","else","for"等。引用某个命名的规则,也可以引用自己。
R1 R2 ... Rn
R1 | R2 | ... | Rn
*R (匹配规则0次或以上)
+R (匹配规则1次或以上)
?R (可选规则,匹配0次或1次)
列表运算符(
R1 % R2):它是R1 *(R2 R1)的简写。例如INT % ","表示由逗号分隔的整数序列。邻接运算符(
R1 ++ R2):它表示R1和R2规则之间没有空白字符或注释。默认运算符优先级是:单目(
*R,+R,?R)>++>%>|。可以用 () 改变运算符优先级。
大部分东西都相对好理解,我们稍微展开讲一下其中的一些细节。
其中,STRING(字符串字面量)有两种形式:
"Hello\nWorld\n"
`Hello
World`其中第一种 "..." 形式的字符串字面量叫 QSTRING,而另一种叫 RAWSTRING。而 STRING 可以看作是它们的组合:STRING = QSTRING | RAWSTRING重点解释一下邻接运算符:R1 ++ R2。由于 TPL 规则匹配默认会自动过滤空白字符和注释,所以 R1 R2 规则不能表达 R1 和 R2 是邻接的(它们之间可能有空白字符和注释)。例如 Go+ 的领域文本规则是 IDENT ++ RAWSTRING,它表示以下这些都是合法的领域文本:
tpl`expr = INT % ","`json`{"name": "Ken", age: 15}`而以下这些能够匹配 IDENT STRING 规则,但它们不是合法的领域文本:
tpl"expr = *INT" // IDENT 之后必须是 RAWSTRING,不能是 QSTRINGtpl/* 注释 */`expr = *INT` // IDENT 和 RAWSTRING 必须邻接,中间不能有空白和注释其二,匹配结果。每个规则都有自己内置的匹配结果。
词和关键字的匹配结果都是
*tpl.Token。R1 R2 ... Rn 的匹配结果是 n 个元素的列表(
[]any)。*R, +R 的匹配结果是列表(
[]any),元素个数要看匹配了多少个R规则。R1 | R2 | ... | Rn 的匹配结果看具体匹配到谁,结果就是匹配到的那个规则的结果。
?R 如果匹配成功结果就是
R的结果,否则是nil。R1 % R2 等价于
R1 *(R2 R1),所以它的匹配结果是 2 个元素的列表([]any),且列表第二个元素还是一个列表([]any),这个列表的元素个数未知,但是每个元素又是一个 2 个元素的列表。所以它实际上是一棵层高为 3 的树型结构。R1 ++ R2 的匹配结果同
R1 R2,是一个只有 2 个元素的列表([]any)。
其三,匹配结果改写(rewrite matching results)。规则默认的匹配结果 TPL 给它取了一个名字叫 self。我们可以用一个 Go+ 的闭包 => { ... } 来改写一个规则的匹配结果。
这一点非常重要,它意味着 TPL 和 Go+ 是无缝配合的。在 Go+ 中,你通过领域文本来引用 TPL。然后在 TPL 中你又可以通过匹配结果改写调用 Go+ 代码。我们看一个例子:
import "gop/tpl"
var vals []int
cl := tpl`expr = int % ","int = INT => { vals <- self.(*tpl.Token).Lit.int! // 将词转为整数并添加到 vals 列表 return nil}`!
echo cl.parseExpr("1, 2, 3", nil)!echo vals你可以在 Go+ Playground(https://play.goplus.org)中输入这段代码并执行,结果如下:
[<nil> [[, <nil>] [, <nil>]]][1 2 3]这个例子它很好地体现了 TPL 和 Go+ 很好的互动能力(比如在 TPL 中给 Go+ 的列表 vals 添加元素),但从工程实践角度并不是一个好例子,因为它硬生生把 “匹配结果改写” 这样一个不鼓励副作用的功能做成了带副作用的 Action(将整数并添加到 vals 列表是一个有副作用的操作)。更好的写法是:
import "gop/tpl"
cl := tpl`expr = INT % "," => { return tpl.ListOp[int](self, v => { return v.(*tpl.Token).Lit.int! })}`!
echo cl.parseExpr("1, 2, 3", nil)!这里我们调用 TPL 提供的 ListOp 函数将 INT % "," 的匹配结果(上文我们提到 TPL 的列表运算符的匹配结果是一颗层高为 3 的树型结构)转为平面的整数列表。
用 Go+ TPL 实现一个计算器?那简直不要太方便(只有不到 30 行的代码):
import "gop/tpl"
cl := tpl`expr = operand % ("*" | "/") % ("+" | "-") => { return tpl.BinaryOp(true, self, (op, x, y) => { switch op.Tok { case '+': return x.(float64) + y.(float64) case '-': return x.(float64) - y.(float64) case '*': return x.(float64) * y.(float64) case '/': return x.(float64) / y.(float64) } panic("unexpected") })}operand = basicLit | unaryExprunaryExpr = "-" operand => { return -(self[1].(float64))}basicLit = INT | FLOAT => { return self.(*tpl.Token).Lit.float!}`!
echo cl.parseExpr("1 + 2 * -3", nil)!更多关于 TPL 的内容,可以查阅 Go+ demo 中以 tpl- 开头的例子:
https://github.com/goplus/gop/tree/main/demo
这些例子包括:如何用 TPL 实现计算器、如何用 TPL Parse 文本生成 AST、如何只用 200 行代码实现一门语言等等。
怎么做架构
我花了较大的篇幅介绍 Go+ TPL 的演进过程。这是因为我觉得它是一个非常好的架构演进的案例。TPL 从 2006 年开始,到今天已经有近 20 年的历史,但直到 Go+ TPL 这个版本,才达到了让我非常满意的状态。
为啥满意,这和我对什么是好的架构的判断标准有关:
解决的问题足够普适,足够大。通用文本处理(Text Processing)是一个很难的领域,目前主流语言对这个问题的答案基本只有一个,就是正则表达式(regexp)。但是正则表达式只能处理简单需求,对复杂文本的处理并不优雅。
解决问题的方法论足够简单,足够通俗易懂,足够好学。理解 TPL 并不比理解正则表达式更难,甚至一定程度上来说更简单。
使用者的心智负担低,坑比较少。
根据我的观察,对于架构一词的范畴,什么是架构,什么是好的架构,如何才能产生好的架构,这些话题在开发者群体中并没有形成足够大范围的共识。
刚好今天晚上 18:30,七牛实训营第三期结营仪式,我会有一个演讲,演讲主题是 “怎么做架构”。感兴趣的同学可微信搜索:七牛实训营。
Go+ v1.3 总结及未来展望
总结一下,Go+ v1.3 的核心更新主要包括:
Go+ Mini Spec 发布
领域文本,尤其是 Go+ 的 TPL 文法的内置支持
支持 import C/C++ 和 Python 包,并支持生成 Wasm 文件
本文重点介绍了 Go+ Mini Spec、领域文本及 TPL。这是 Go+ v1.2 推出正式版本的 classfile 之后,Go+ 在领域友好(SDF)问题上的又一重大举措。
在领域友好这件事情上,Go+ 的完整哲学是:
不鼓励定义领域专用语言(DSL),我们鼓励用 classfile 定义领域知识。
支持常见的各类主流领域文本,让它们和 Go+ 代码更加自然协同。
Go+ v1.3 是 Go+ 发展上很重要的里程碑。Go+ 的三合一:

至此已经只差最后一小步,实现与 Python 生态的完美兼容。支持 import Python 库解决了最难的一步,但后续还有非常多的工作要做。
所以 Go+ v1.3 之后下一步是什么?
我内心的答案是,快速到达 Go+ v1.5 版本,解决 Go+ 三合一的最后一公里,实现与 Python 生态的完美兼容。在 Go+ v1.0 发布会上,我对 Go+ RoadMap 的描绘是将在 Go+ v1.7 版本实现这一目标,而今天这一进程正在被极大加速。
未来,值得期待。
