
开发者不必等!DeepSeek-R1-Distill 蒸馏版模型全面上线
上周,DeepSeek-R1 671b 全参模型上线七牛云,开发者们对 DeepSeek 的强大性能赞不绝口,同时也提出了对蒸馏模型的需求。今天,我们带着 DeepSeek-R1 蒸馏版模型全面上线的好消息又来了。
一键部署,轻快 Build!
响应开发者诉求,蒸馏版模型来袭
感谢 DeepSeek 团队开源的多种模型,七牛云会根据您的场景需求,搭配不同模型,推出最具有性价比的解决方案,告别官方 “服务器繁忙”。
我们深知开发者对于灵活部署和高效开发的需求,因此,DeepSeek-R1 蒸馏版模型全面上线了!开发者可以根据自身需求选择不同参数规模的蒸馏模型,无论是资源有限的小团队,还是追求极致性能的大企业,都能找到适合自己的版本。
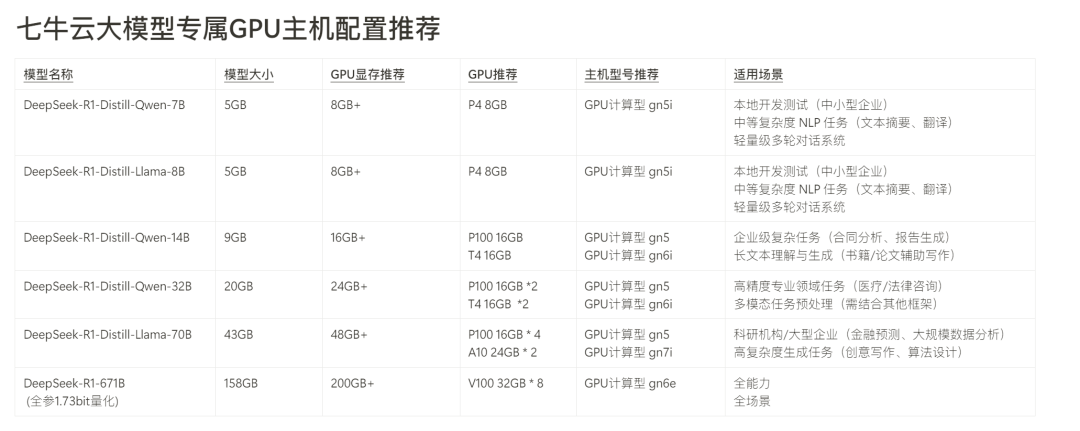
DeepSeek-R1-Distill 系列:轻量化推理模型
应用场景:由于其轻量、高效的特点,适合在计算资源有限的设备上运行。适合中小企业和开发者进行本地部署,快速应用到实际业务。
一键部署 DeepSeek-R1 蒸馏版
# 镜像打开后 等待脚本自动下载、配置模型即可#7B模型docker run --gpus all -it registry-aigc.qiniu.io/miku-aigc/deepseek7b_ollama_lite:0.1.0 #8B模型docker run --gpus all -it registry-aigc.qiniu.io/miku-aigc/deepseek8b_ollama_lite:0.1.0#14B模型docker run --gpus all -it registry-aigc.qiniu.io/miku-aigc/deepseek14b_ollama_lite:0.1.0 #32B模型docker run --gpus all -it registry-aigc.qiniu.io/miku-aigc/deepseek32b_ollama_lite:0.1.0 #70B模型docker run --gpus all -it registry-aigc.qiniu.io/miku-aigc/deepseek70b_ollama_lite:0.1.0
满血版回顾,DeepSeek 的技术突破
最后,我们再来回顾下满血版,为什么我们首先上线 DeepSeek-R1 671b 全参模型呢?我们希望各位开发者能在自己的应用中集成媲美官方版 DeepSeek-R1 的顶尖推理能力,同时致敬 DeepSeek 在技术架构上敢为人先的创新精神:
杀手锏一:混合专家模型(MoE)
仅需激活少数专家模块即可完成任务,推理算力需求减少 4 倍以上,特别适合高并发场景(如智能客服、实时数据分析)。
杀手锏二:多头潜在注意力机制(MLA)
将历史数据处理的内存占用压缩至传统模型的 1/4-1/8,显著提升长文本处理效率,降低云服务商的硬件投入成本。
DeepSeek-R1 671b 全参数推理模型
应用场景:适合企业级高精度推理需求
DeepSeek R1 的性能与 OpenAI 的 o1 版本相当,在多项基准测试中表现优异,例如在 AIME 2024、MATH-500、Codeforces Elo 等任务中,DeepSeek R1 的得分均高于或接近 OpenAI o1。
强大的推理能力和数学、代码生成能力使其适合复杂逻辑任务,如科研数据分析、算法开发、教育辅导等。
七牛云主机推荐:1.73-bit 量化版本
GPU 显存:200GB+;需要分布式多卡并行(如 8x A100 40GB 或 8x V100 32GB 或 10xA10 24GB)
内存:最低 512GB
磁盘:最低 400GB,推荐 1T(磁盘比较便宜)
CPU:最低 64 核
一键部署 DeepSeek-R1 满血版
# 镜像打开后 等待脚本自动下载、配置模型即可docker run --gpus all -it registry-aigc.qiniu.io/miku-aigc/deepseek_ollama_lite:0.2.0为了便利开发者接入 DeepSeek,我们特别推出适配 DeepSeek 的 GPU 云服务器专项折扣!限时优惠!DeepSeek GPU 云服务器,买 10 个月送 2 个月,全年 AI 高效加速!
