
打破算力瓶颈:Kimi K2.5视觉模型在七牛云的高效落地实战
在多模态大模型爆发的今天,开发者面临的挑战早已从“找不到好模型”变成了“如何用得起、跑得快”。Kimi K2.5视觉模型凭借其出色的长文本理解与精细图像识别能力,正在成为构建视觉智能体的新宠。然而,对于大多数中小团队而言,自建GPU集群的高昂成本和复杂的运维压力,往往是阻碍项目落地的最大绊脚石。相比于盲目堆叠硬件,选择一个能够提供稳定算力且兼容主流API标准的云平台,才是打破性能瓶颈的关键。本文将深入探讨如何利用七牛云的基础设施,实现Kimi K2.5视觉模型的高效部署与推理加速,让视觉多模态能力真正落地到业务场景中。
视觉多模态的算力突围战
传统的视觉分析方案往往依赖于单一功能的CV模型,识别物体需要一个模型,OCR文字提取需要另一个,这种拼凑式的架构不仅维护困难,而且难以处理复杂的语义理解任务。Kimi K2.5视觉能力的引入,彻底改变了这一局面。它不再是简单的“看图说话”,而是能够理解图像中的隐喻、逻辑关系甚至长文档细节。
但在实际落地中,许多开发者发现,本地部署这类大参数量的多模态模型,推理延迟往往高达数秒,严重影响用户体验。这就需要借助云端的弹性算力。通过对接七牛云的AI大模型推理服务,开发者可以直接调用经过优化的推理节点,无需关心底层的显存分配与模型切片。这种服务模式不仅完美兼容 OpenAI 和 Anthropic 双 API,还支持深度思考模式,这意味着你可以像调用普通文本接口一样,轻松集成复杂的视觉推理能力。
Kimi K2.5视觉API对接实战
要实现Kimi K2.5视觉API对接教程中描述的高效流程,第一步是获取稳定的鉴权凭证。许多开发者习惯于在代码中硬编码密钥,这在生产环境中极不安全。推荐的做法是利用七牛云提供的密钥管理系统。
访问控制台获取七牛云API key后,你可以立即获得最高 600 万免费 Token 的测试额度。这个Key不仅仅是身份验证的工具,它还兼容了OpenAI的SDK标准。这意味着,如果你原本有一套基于GPT-4o-vision的代码,只需更改base_url和api_key,就能无缝切换到Kimi K2.5的视觉服务上,几乎不需要重构代码。
在处理高并发的图像请求时,七牛云GPU加速视觉模型推理的优势尤为明显。比如在一个电商商品自动打标的场景中,系统需要在一分钟内处理上千张商品图。通过云端的高吞吐推理集群,可以将单张图片的解析时间压缩到亚秒级,同时保证识别的准确率。
从“看图”到“懂图”:构建智能体闭环
单纯的模型推理只是第一步,真正的商业价值在于构建完整的基于Kimi K2.5的视觉分析方案。例如,在一个保险理赔的智能体开发场景中,用户上传一张车祸现场的照片,智能体不仅要识别车辆受损部位(视觉识别),还要结合保险条款判断赔付范围(逻辑推理),最后生成定损报告(文本生成)。
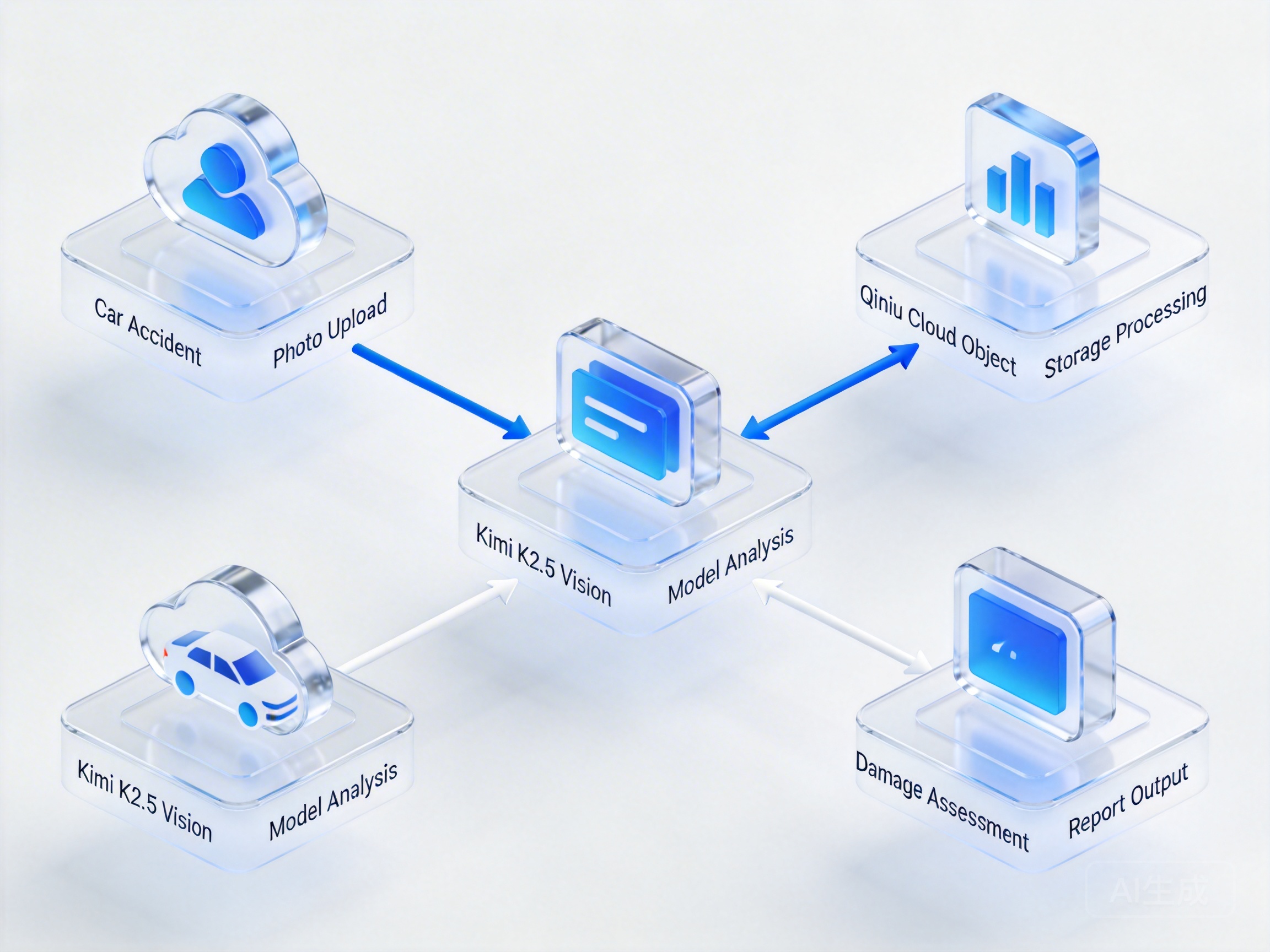
在这个链路中,图像的前处理至关重要。过大的图片会增加网络传输耗时,而过小的图片又会丢失细节。这时可以结合七牛云的智能多媒体服务(Dora),在图片送入大模型之前,自动进行智能瘦身、去噪或区域裁剪。这种“传统CV预处理 + 大模型深度理解”的组合拳,既降低了Token消耗,又提升了最终的分析效果,是实现Kimi K2.5多模态模型私有化部署替代方案的最佳实践。
与其花费巨资搭建私有算力,不如善用云端成熟的工具链。通过合理的API调度与多媒体处理服务的配合,你完全可以在控制成本的前提下,构建出具备顶尖视觉理解能力的AI应用。
