
算力账本拆解:开源的Llama 3微调和直接调用商业大模型API哪个更省钱?
当企业准备将大模型接入实际业务时,技术负责人通常会面临一个灵魂拷问:开源的Llama 3微调和直接调用商业大模型API哪个更省钱?很多团队在做预算时,往往只盯着硬件采购价格或按Token计费的账单,却忽略了工程化落地过程中的隐性消耗。今天我们就把这笔算力账本彻底拆解开,看看不同业务场景下的真实成本到底长什么样。
企业级Llama 3微调GPU算力成本怎么算
要搞清本地部署开源模型算力成本分析,我们不能只看显卡的标价。以微调一个Llama 3 8B模型为例,如果使用全量微调,至少需要配置多张A100或H100显卡。即便采用LoRA等参数高效微调技术,单张A100(80G)也是起步门槛。按目前云厂商的算力租赁价格,单卡月租金通常在万元上下。
但这仅仅是硬件开销。低成本大模型微调实践中,最昂贵的是人力与时间。你需要配备专门的算法工程师来清洗数据、调整超参数、评估模型效果。如果算上工程师薪资、试错过程中的空转算力,一次基础的微调实验成本轻松突破五万元。更别提后续的模型量化、推理加速以及高并发下的负载均衡问题。
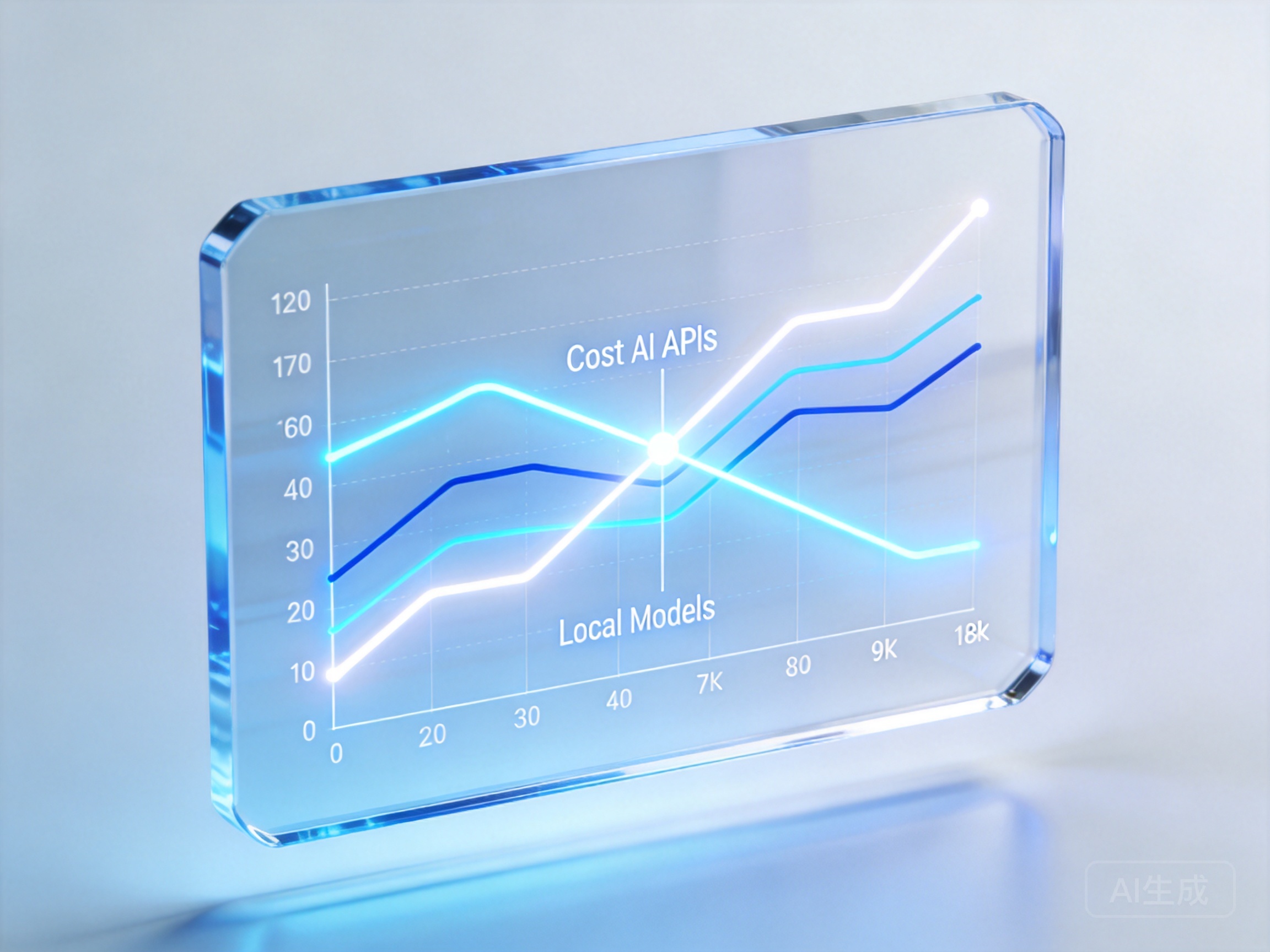
大模型API调用与本地私有化部署隐性成本对比
与自建算力池相比,按需付费的API调用在初期显得极具性价比。商业大模型API免去了繁琐的环境配置和硬件维护,开发者只需几行代码就能让应用跑起来。开源大模型部署成本对比的核心在于请求量级:当你的日均Token消耗量在千万级别以下时,API调用的总成本远低于养一个算法团队和几台GPU服务器。
然而,过度依赖单一商业API也会带来风险。一旦供应商调整定价策略或服务出现波动,业务就会陷入被动。因此,中小企业大模型落地选型指南与避坑教程中经常强调,不要把鸡蛋放在同一个篮子里。你需要一套灵活的架构,在不同模型之间无缝切换。
如何利用统一API接口降低多模型切换费用
为了平衡成本与稳定性,越来越多的团队开始采用聚合路由策略。与其在代码里硬编码各种不同厂商的SDK,不如通过统一的标准接口来管理调用。这不仅能有效降低研发对接成本,还能根据实时报价动态路由请求。
在这个思路上,七牛云 AI 大模型推理服务提供了一个绝佳的落地方案。它完美兼容OpenAI和Anthropic双API标准,集成了Claude、Gemini、DeepSeek等顶级模型。开发者无需修改底层代码,就能一站式接入多个大厂能力。对于预算有限的团队,平台体验即送的300万Token足以覆盖产品早期的测试与验证阶段。
如果你需要对不同项目的额度进行精细化管控,配合七牛云 API Key 管理服务可以实现极高的管理效率。它支持一键创建密钥并激活最高600万免费Token额度,覆盖从文本推理到OCR、TTS的全栈AI能力。这种统一入口的模式,直接省去了企业多头采购、多头结算的繁琐财务流程。

算力选型从来不是非黑即白的单选题。对于绝大多数处于探索期和成长期的业务,先用成熟的API跑通商业模式,利用统一平台进行多模型调度,是控制试错成本的最优解。当特定场景的请求量形成规模,且通用模型无法满足垂直领域的精度要求时,再切入开源模型的精细化微调,才是符合商业逻辑的演进路线。
