
柴树杉:如何基于 Go 语言和 Go 编译器定制语言
 大家好,本次分享的主题是「Go 编译器定制简介」,希望可以由浅入深让大家对 Go 的编译器有一个整体的认知,不要认为编译器太难了无从下手。
大家好,本次分享的主题是「Go 编译器定制简介」,希望可以由浅入深让大家对 Go 的编译器有一个整体的认知,不要认为编译器太难了无从下手。

我从 2010 年 Go 语言发布后便开始关注这门语言,后续因为个人的兴趣驱动,一直在研究和探索 Go 语言以及语法树、编译器领域。我也出过几本书,写书的原因是当我不懂某个领域时,可以通过写书的过程来学习其中的技术,如果熟悉某个领域,反而可能没有写书的动力。

回到今天的分享。大纲如下:
最简编译器
编译器后门八卦
Go 和 Rust 的选择
Go 衍生的语言
Go 语法树
Go 类型系统
SSA 和 LLVM
µGo 案例
参考链接
一. 最简编译器
《编译原理》(龙书)的作者在今年获得了图灵奖,这个作者最开始是在贝尔实验室工作,他将工作的一些成果编写成了这本书的内容。在编译器领域,龙书是排名第一的参考书,但这本书中理论太多、太大,导致很多人会比较畏惧去搞一个编译器。
但我想说一个观点,也是一位来自日本的 rui314 大佬在他的电子教程中所展示的观点 —— “编译器入门可以很简单”。
关于编译器是什么,我总结了以下几个观点:
- 编译器是一种精确的翻译程序
- 编译器输入的是数据序列, 输出的也是数据序列
- 编译器作为可执行程序可用于 AOT 翻译, 类似 gcc 命令
- 编译器也可以是一个函数, 用于 JIT 运行时翻译, 或者包装为 AOT 翻译命令
- 编译器一般是某种编程语言的翻译程序, 因此也就包含了编程语言的外延
- 现代编程语言不仅仅是翻译, 还有内置的运行时调度
- 编译器可以很复杂, 甚至可以内置 OS ...
- 编译器也可以很简单...
首先,编译器是一种翻译程序,执行逻辑类似于输入“你好”即可翻译成英文的“Hi”,大家可以理解成输入一个字符串,输出的也是一个字符串。比如将小写的 abc 转换成大写的 ABC,这也是一种翻译,但因为输出的 ABC 不能执行,大家不会将其看做是编译器。
编译器一般是产生可执行程序,用圈内人的术语来说叫做 AOT 翻译,也就是将程序翻译成可执行程序后再执行,类似 gcc 程序。和 AOT 对应的是 JIT,在 Java 语言中比较常见,是在执行过程中再进行翻译。
一门编程语言在有了编译器后,一般才会被认为是可用的,才可以用这个语言编程。因此编译器作为编程语言的翻译程序,通常会包含编程语言的外延,比如 Go 语言中 goroutine 这类内置的运行调度。
所以编译器也可以很复杂,甚至可能内置 OS。Go 语言早期有一个版本是可以跑在裸机中的,包含 go routine 调度,实际上就是一个 OS 的雏形。
当然编译器其实也可以很简单。我们举一个「人肉编译器」的例子。这个例子仿自日本编译器大佬 rui314 的一个教程:
将一个整数编译为一个程序, 程序的返回值返回这个整数值。比如 42 翻译为以下的 C 语言程序,这个程序可以执行,但只返回一个状态码:
int main() {
return 42;
}
也可以翻译为以下的 X86 汇编程序,同样返回一个状态码:
.intel_syntax noprefix
.globl _main
_main:
mov rax, 42 ;
ret
也可以翻译为 LLVM 跨平台的汇编程序:
define i32 @main() {
ret i32 42 ;
}
上述操作实际上就是编译器。但因为比较简单,我称为「人肉编译器」,可以通过人工的方式,用几行代码来实现。
但「人肉编译器」其实只是打造编译器的第一步。任何编译器首先都是我们在人脑里构想一个翻译的思路,再通过程序将思路进行实现。那么第二步,我们用 Go 程序来替代人肉编译器:
func main() {
code, _ := io.ReadAll(os.Stdin)
compile(string(code))
}
func compile(code string) {
output := fmt.Sprintf(tmpl, code)
os.WriteFile("a.out.ll", []byte(output), 0666)
exec.Command("clang", "-o", "a.out", "a.out.ll").Run()
}
const tmpl = `
define i32 @main() {
ret i32 %v
}
`
编译 echo 123 | go run main.go,
执行 ./a.out,
看结果 echo $?
通过这种方式,我们实现了将一个整数翻译成可执行程序并执行,也就实现了一个最简编译器。
但这个最简编译器太简单了,有兴趣的朋友可以来挑战前进一小步。这一小步将涉及到了很多编译器的本质:
输入的数字变为支持加/减/乘/除法和小括弧的表达式(词法+语法解析)
输出 X86 汇编时如何处理多个中间结果?
如何简化优先级的处理?
简单的加减乘除表达式运算,其实是编译器中最复杂的能力之一。据说在 60、70 年代,大家对表达式的解析持悲观态度,当时是一个非常难的问题。而在真正实现之后,大家却觉得非常简单。感兴趣的朋友,也可以尝试一下用简化的方式处理表达式运算中的优先级。
二. 编译器后门八卦
1. Reflections on Trusting Trust - 01 - 自重写程序
上图左侧为 Unix 之父汤普森,右侧为丹尼斯·里奇。里奇和乔布斯在同一年去世,是非常低调的 C 语言之父。
标题中的「Reflections on Trusting Trust」中文翻译为「信任的反思」。这是汤普森在 1983 年获得图灵奖时做的获奖报告,报告文档大概只有 2-3 页,但这篇论文非常重要,建议大家看一看。其中分享了 3 个有意思的程序。
首先就是上图中用 C 语言实现的自重写程序,这个程序执行后会打印出自身代码。大家知道生命和病毒一样,是可以克隆的,但很神奇的是软件程序竟然能够克隆自己,特别这是一个不能自动执行的代码。
我简单介绍一下上图中代码的思路。图片左侧是一个 char 数组,右侧是一个 main 函数。函数中的前两个 printf 会将左侧的代码进行复制,第三个 printf 会将左侧代码作为字符串进行打印。
之所以通过两次简单的打印便能复制自己,核心在于左侧代码中的内容。s 是从最后一个 0 到结尾的内容, 第 1 和第2个 printf 打印 s 数组, 第 3个打印后面部分。左侧代码其实是从第二个 0 开始,执行右侧代码。
程序看起来虽然是一个“死”的东西,但配合编译器执行竟然可以实现复制自己,就像被注入“灵魂”一样。
2. Reflections on Trusting Trust - 02 - 鸡和蛋问题
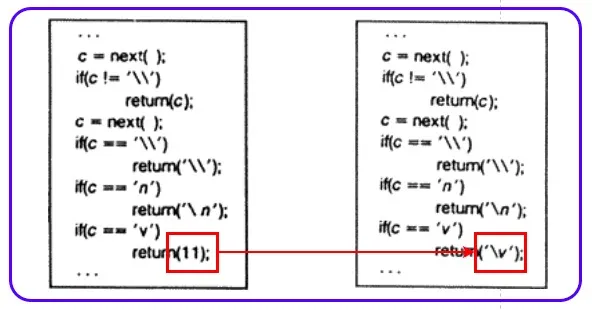
第二个问题是鸡和蛋的问题。上图左侧红框中的 11,在右侧如何对应到了 \v?
这里要说明一个背景。我们现在写编译器很轻松,任何的语法都可以自由使用。但汤普森在上世纪 70 年代开发 C 语言编译器时还没有太多的工具。比如给 C 语言编译器增加转义字符的支持时,编译器本身不支持写转义的 \v 时,无法进行编译,这时只能先输入一个整数 11,将编译器自身编译为可执行程序,赋予\v 转义的值 (11),然后将 11 改写为 \v 使得代码更直观,再用刚才的二进制程序进行重新的编译得到更强的二进制编译器,然后编译器本身代码才可以用新的语法。
这其实就是 C 编译器为了支持转义实现的自举过程,类似于武侠小说中左脚踩右脚上升的武功。当年汤普森用 C 语言开发 C 语言编译器中的自举,难度是极高的。正如我们标题所写鸡和蛋的问题,答案大家都很清楚是先有蛋后有鸡,但这个蛋不是鸡蛋,是很像鸡蛋却不是鸡蛋的蛋,是很像 C 语言编译器,但不断迭代演进才完成的具备完整 C 语言语法写的 C 语言编译器。
3. Reflections on Trusting Trust - 03 - 潜伏的后门
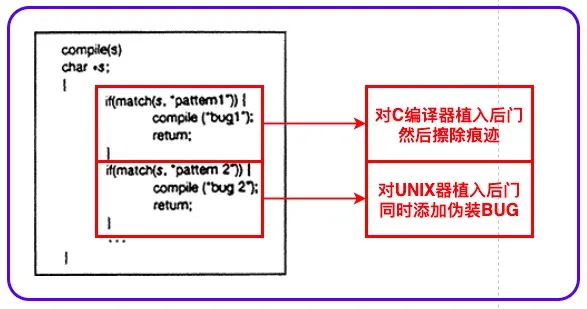
前面两个案例提到的自重写与自举,本质上都是改变程序。汤普森还分享了第三个程序。
左边的函数叫 Compile,其中定义了两个 if 语句的模式匹配,分别插入一个 bug。第一个 if 语句中实际上是判断当用户用程序编译自己时,为编译器内部注入一个 bug.一个后门;用这个有 bug 的编译器编译 UNIX,会为 UNIX 也植入一个后门,同时在unix自身代码添加伪装 bug。
听起来好像很厉害,但这个操作真正高明的地方并不在此。汤姆森在将编译器插入 bug 代码后,将编译器本身从代码编译出带后门的二进制编译器,然后删除这两个“包含后门的” if 语句,接下来用被污染了的 C 语言编译器的二进制程序来编译代码,使得即便没有这两个 if 也能将 bug 植入进去,保证后续的编译器一定会留有最开始植入的后门,级联传递给后面的c编译器和unix输出的二进制程序。
当时贝尔实验室的 Unix 操作系统都是用汤普森写的编译系统进行编译,有一天有人有发现账号被汤普森入侵,意识到 Unix 系统有后门,在修改后门后却发现汤姆森还是可以入侵他的账号,这些大佬都很郁闷,不知道怎么回事。
其实汤姆森虽然在 Unix 操作系统植入了后门,但这只是第一层伪装。真正厉害的后门是在编译器的二进制中,通过带后门的二进制编译出大家使用的 Unix 操作系统。这就使得操作系统哪怕本身没有后门也可以不断的加入后门。
大家知道,编译成二进制后都是汇编代码,代码量非常庞大,很难通过人工的方式检测到。这个秘密直到 1983 年汤姆森在图灵奖的获奖演讲中才披露出来。
几年前,XCode 也被用类似的方式植入了一些后门。这三个八卦小故事和编译器是非常相关的。
4. 更多的自重写代码
关于自重写代码,还有两个例子。
main(a){printf(a="main(a){printf(a=%c%s%c,34,a,34);}",34,a,34);}
上述代码可能是最短的 C 自重写代码,大家可以自己尝试理解一下。
package main
import "fmt"
func main() {
fmt.Printf("%s%c%s%c\n", q, 0x60, q, 0x60)
}
var q = `package main
import "fmt"
func main() {
fmt.Printf("%s%c%s%c\n", q, 0x60, q, 0x60)
}
var q = `
上述是 Go 语言社区 rsc 提供的一个 Go 版本的自重写代码,Go 以及自举了,大家可以放心使用。就算有后门我们也发现不了,可以当做没有后门使用
三. Go 和 Rust 的选择
我们对使用 Go 和 Rust 开发编译器的优缺点,进行简单的对比。我检索了 GitHub 中 Go 开发的编译器( https://github.com/topics/compiler?l=Go ),基于 Go 语法衍生的主要有:
TinyGo 9.1K:面向单片机的 Go 通用语言
Go+ 7.9K:基于 Go 额外增加新语法,是 Go 的超集
CUE 3.2K:面向配置的语言
相对独立的主要有以下几个:
Terraform 30.6K Star
esbuild 29.5K Star
Google/Grumpy 10.4K Star: Python 翻译到 Go
Google/SkyLark 1.2K Star: Python 子集
Google/Jsonnet 1.1K Star
Google/CEL 1K Star: 表达式语言
OPA/Rego 6K Star: 策略语言
GopherLua 4.5K Star: Lua 实现
同样,我也检索了 GitHub 中 Rust 开发的编译器( https://github.com/topics/compiler?l=rust ):
SWC 19K Star: TypeScript 编译器
Facebook/Move 16.3K Star: 区块链语言
RustPython 10.3K Star
solang 500 Star: Solidity 编译器
ulisp 30 Star
Rust 我用的时间不长,所以列的应该不全,给我的感觉目前 Rust 社区对 VM 和 Compiler 的开发比较活跃。
下面我们将二者进行一下对比:
Go 编译快, GC 简化开发, 运行较快, 非常适合写编译器
Rust 编译慢, 开发繁琐, 运行时稍快(但过早释放内存影响性能), 不是编译器的最佳选择
如果真有死磕 Rust 语言的毅力/能力/精力, 建议去写 Rust 编译器本身
Rust 比较适合开发长时间稳定运行的 VM 系统, 比如各种 WASM 虚拟机
Go 比较适合开发快速迭代, 一次完成 AOT 编译的编译器, GC 一次回收效率更高
虽然 Go 不一定是最理想的编程语言,但如果让我选择,我会选择从 Go 开始入手。因为开发编译器本身就是一件非常难得工作,最开始便追求极限很可能刚完成 1% 便夭折了。所以还是先稍微退一步,把事情做完比较合适。最起码在最开始的阶段,性能不是最重要的。
推荐大家两篇文章,作为补充阅读:
- esbuild为什么不用Rust,而使用了Go?
https://www.zhihu.com/question/439945314
- 写Rust的我们丢掉了什么
https://zhuanlan.zhihu.com/p/405160594
四. Go 衍生的语言
我们举几个例子:
TinyGo 9.1K Star: 单片机环境的 Go
Go+ 7.9K Star: Go 之上增加了新的特性
CUE 3.2K Star: 配置语言
Tengo 2.5K Star: Go 类似语法的脚本语言
Emgo 950 Star: 面向嵌入式环境的 Go
µGo 700 Star: 如何从头定制 Go 子集
衍生语言的意思,就是语法树以及实现和 Go 非常相似。比如 TinyGo 的代码有很大一部分便是基于 Go 补充一些后端的拓展,可以说是站在 Go 这个巨人的肩膀之上。大家比较熟悉的 Go+ 也是如此,有很多地方的思路和 Go 一致,这也是大家认可的一种方式。
值得一提的是 CUE 在配置语言领域已经形成了一定的影响力, 作者是 Go 团队成员, 前 BCL 成员,阿里开源的 KubeVela 也是基于 CUE 构建。
我们以 TinyGo 为例,来看一下编程语言的编译器架构。
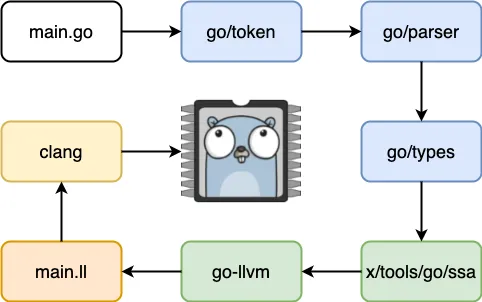
TinyGo 的编译器架构很有代表性,和 Go 本身也很类似。简单来讲就是一个 Go 的程序 main.go 通过 go/scanner 结合 go/token 进行词法解析,然后交给 go/parser 进行语法解析并产生语法树,通过 go/types 进行语义解析,通过 x/tools/go/ssa 将 Go 的 AST 翻译成 ssa(类似汇编的中间码) 的模式,调用 go-llvm 翻译成 llvm 形式的 main.ll,最后通过 clang 翻译到单片机环境中。
通过这个流程,大家就对编译器的每个环节都比较熟悉了。如果涉及到多个 Go 文件,同样也是按照这个顺序进行。
五. Go 语法树
1. FileSet 文件集模型
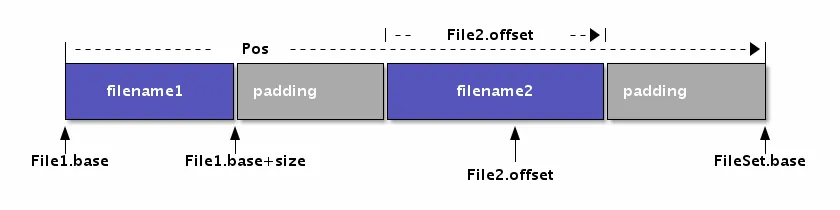
刚开始看语法树时大家都很清楚,一个标号可以是一个标识符、一个整数、一个字符串,但 Go 的 token 包中有一个东西很奇怪,叫做 FileSet 文件集模型。
FileSet 不仅在 Go 的编译时需要,在运行时同样也需要。当 Go 运行时遇到异常 panic,可以打印出行列位置,也就是每一次函数调用的位置。这个位置的获取不是保存一个文件的名称加上行列号位置,这样的实现性能太低并且很占用体积。而 Go 实际只存了一个 uint32 的数值,也就是 FileSet中的下标索引,根据 FileSet 可以反向计算出对应哪一个文件的哪一行、哪一列。
具体实现有如下四步:
1. 全部 Go 文件根据文件名排序
2. 全部 Go 文件映射到连续的抽象内存, 每个文件对应一个区间
3. token.Pos 表示一个指针, 0 对应 token.NoPos 空指针
4. 这样设计的目的是为了压缩和性能, 通过一个 uint32 可以映射到文件位置
这样的操作对于运行时存储或编译语法树中的保存都很便利,速度和性能也有所优化。
2. 全部的 Token 类型

上图中是 Go 全部的 Token 类型,我不展开讲解,但分享一个编译器领域的经验。遇到错误怎么办?先不报错,作为一种特殊的不能被识别的 Token 表示出来,留给后面做处理。这样可以简化时码的词法解析工作。
3. 表达式的语法树
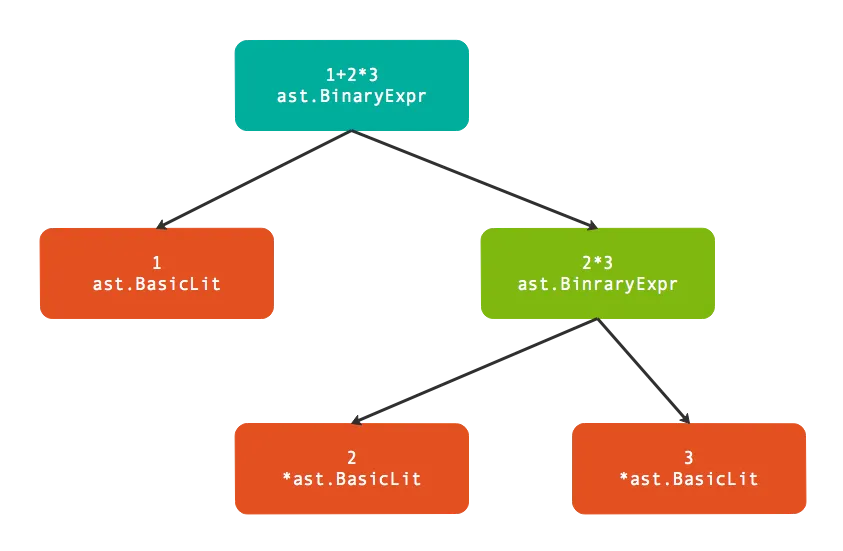
表达式 1+2x3 中,大家都知道需要先计算 2x3,那么在语法树中应该如上图所示体现。通过在树中的体现,编译成语法树时便不再需要小括号的信息。
4. 语法解析器接口
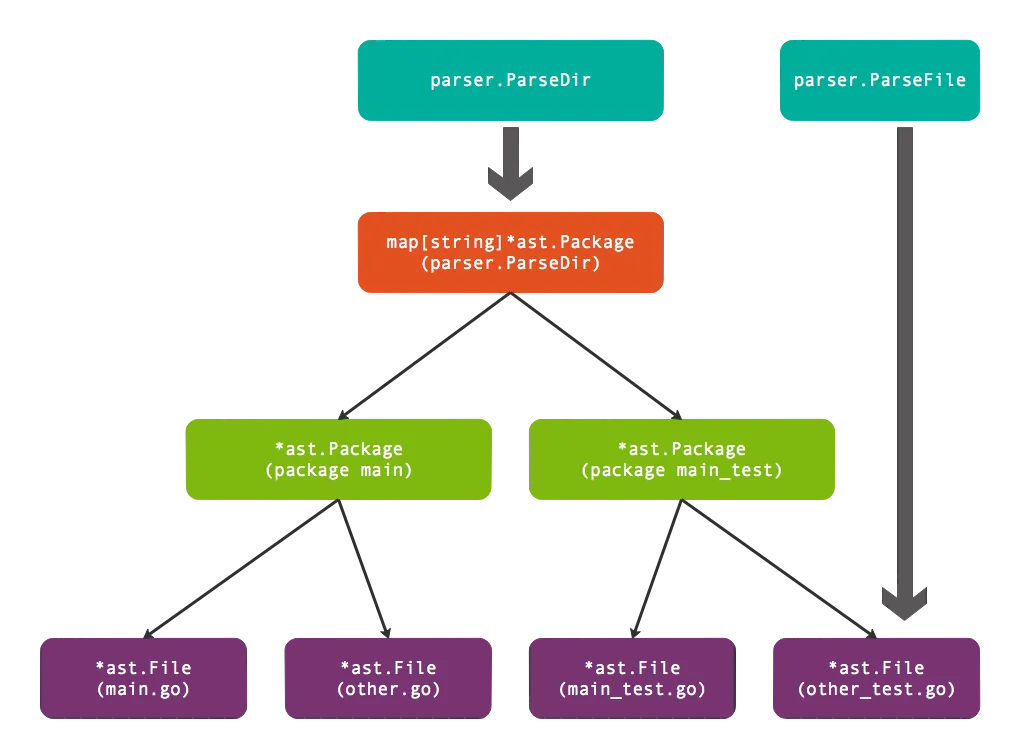
对于语法树大家有一个直观的概念,就是要看语法解析器的入口 parser 在哪里。parser 包含两个函数,第一个是 parser.ParseDir,把一个目录解析成 ast.Packages,另一个是 parser.ParseFile,解析成一个文件。
其中 parser.ParseDir 返回的结果,实际上是一个 main 对应的 package。这里有些奇怪,为什么一个目录只有一个包,但返回的map类型好像存在很多包?其实这里确实存在多个包,因为语言特性的增加导致 API 看起来有些复杂化。
Go 语言的 test 当中确实存在两个包,如果不考虑 test 包的情况,对应一个 package 就可以了。package 的内部有很多的 File,这是文件所对应的函数,也就是 parser.ParseFile 返回的结果。
5. 方法声明的语法树结构
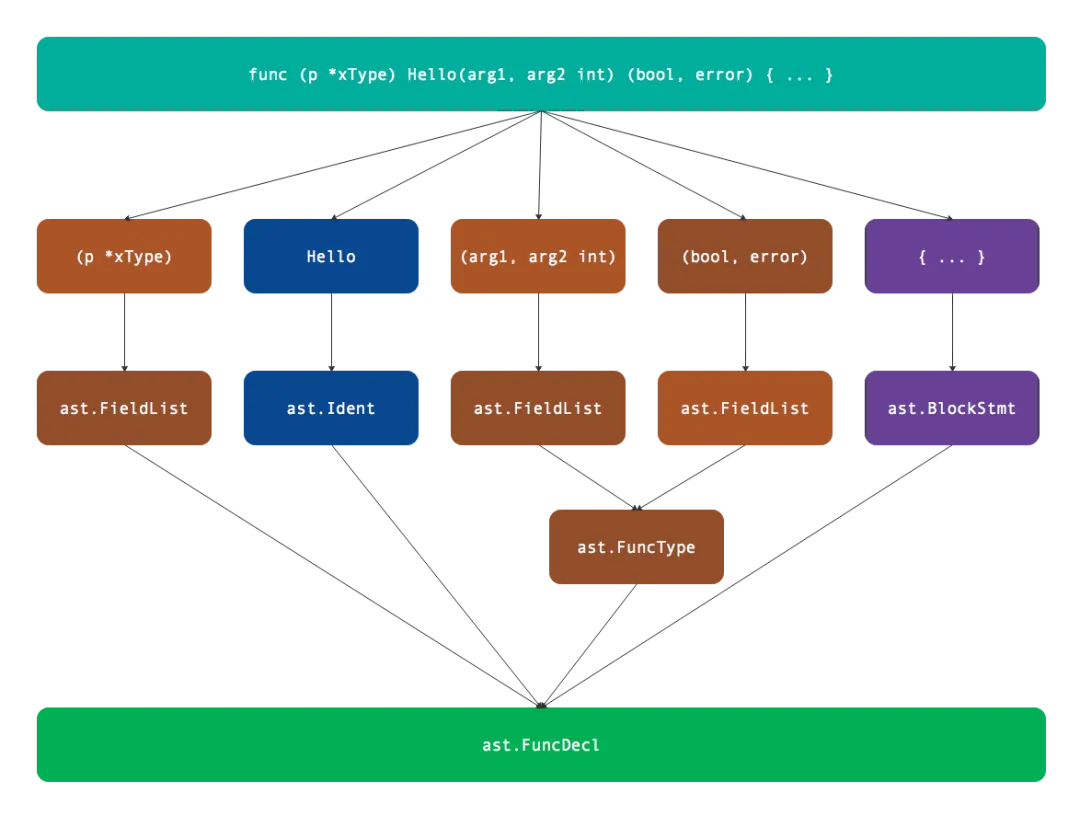
方法实际上是函数的一个超集,大家可以把函数看作方法的一部分。上图中,func 是关键字,信息部分是将接受者列出来。返回型是个 bool 型的 error,参数和返回值打包成 FuncType。
六. Go 类型系统
1. Scope 词法域
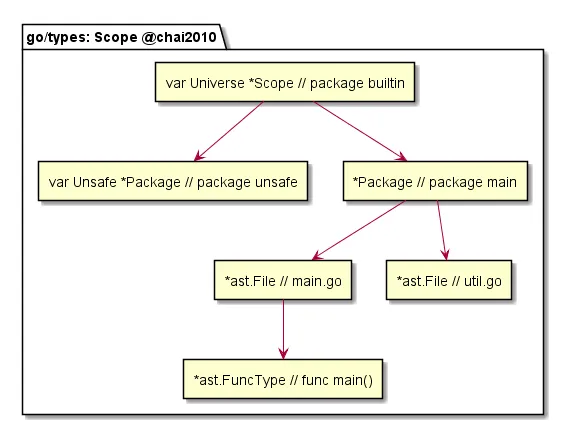
大家知道,语法树列出的内容是固定的。我们举个例子,在今天的分享中我们说「许大」,大家都知道是许式伟老师,但放在更宽泛的领域中,「许大」就会存在重名的问题。这就是系统类型中首先要解决的问题 —— Scope 词法域。
在 Go 语言中,Scope 的最外层叫 builtin,也就是 println函数定义的空间。再往下就是 package,然后是 File,最后是函数。所以词法域的嵌套逻辑是:
builtin -> package -> file -> func
如果在 func 中存在 arg 的名称找不到,便可以逐层向上寻找。
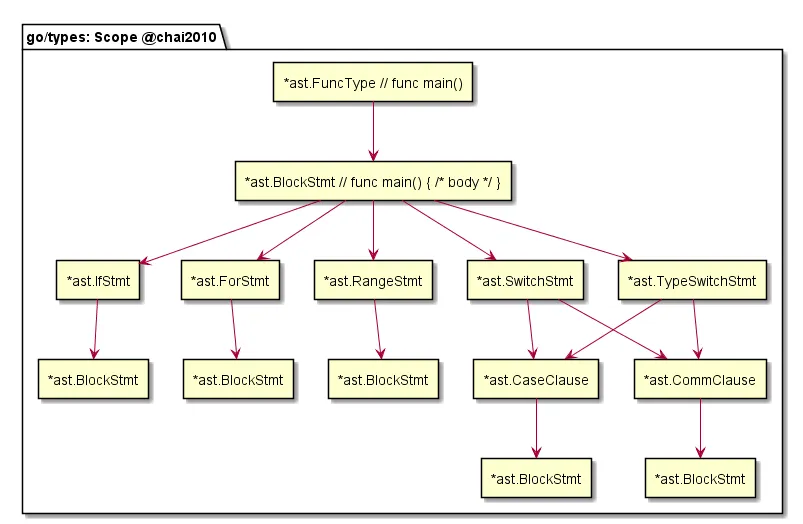
上图为在 body 内部中的流程。看起来很复杂,但对应的其实就是 Go 的各种语法结构。只要可以产生新的命名实体的地方,就会有新的 Scope 产生。这里的嵌套逻辑如下:
func -> args -> block
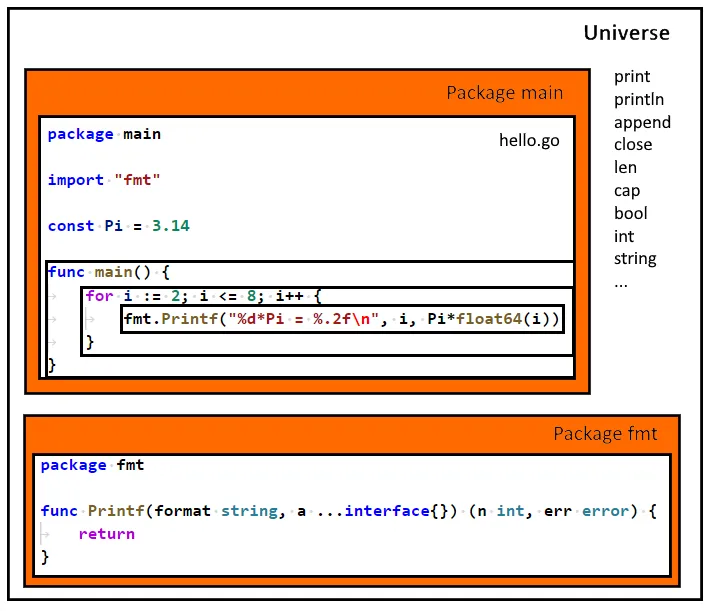
上图是词法域的直观展示。在 func main() 中大家可以看到逐层的嵌套。特殊的地方是 Pkg 内 File 之间的命名实体可见(但不包含 import)。
2. Go 类型检查
有了词法域后,可以解释名称指向谁的问题,可以找到最近的命名的实体。有了实体后,便可以进行类型检查。
类型检查的第一步,是把类型建立出来。Go 语言的基础类型包括 bool/int/float/string/slice/struct/interface,所有的这些类型可以看做是有向无环图的拓扑排序,做的事情就是遍历 AST, 判断 赋值/函数参数/返回值/表达式 类型匹配。
下述代码中,便通过 Go 中的 types 包进行相关操作:
func main() {
fset := token.NewFileSet()
f, err := parser.ParseFile(fset, "hello.go", src, parser.AllErrors)
if err != nil {
log.Fatal(err)
}
pkg, err := new(types.Config).Check("hello.go", fset, []*ast.File{f}, nil)
if err != nil {
log.Fatal(err)
}
_ = pkg
}
const src = `package main
func main() {
var _ = "a" + 1
}
`
对这部分感兴趣的朋友可以查阅代码。很多朋友对 GC 垃圾回收很感兴趣,其实垃圾回收底层的算法和类型系统实际上是一样的,是同一种算法。
3. Go 类型信息
完成类型检查后,中间就会产生类型信息。那么类型信息如何关联到语法树呢?要明确一个概念,Go 中 AST 的每个节点实际上都是一种指针,这个指针作为 key 可以映射到 types.Info 中的 Types 的 map 中。go/types.Config.Check 可为 AST 每个表达式节点标注类型信息。
func main() {
fset := token.NewFileSet()
f, err := parser.ParseFile(fset, "hello.go", src, parser.AllErrors)
if err != nil {
log.Fatal(err)
}
info := &types.Info{
Types: make(map[ast.Expr]types.TypeAndValue),
Defs: make(map[*ast.Ident]types.Object),
Uses: make(map[*ast.Ident]types.Object),
Scopes: make(map[ast.Node]*types.Scope),
}
conf := types.Config{Importer: nil}
pkg, err := conf.Check("hello.go", fset, []*ast.File{f}, info)
if err != nil {
log.Fatal(err)
}
_ = pkg
}
七. SSA 和 LLVM
1. SSA 基本结构
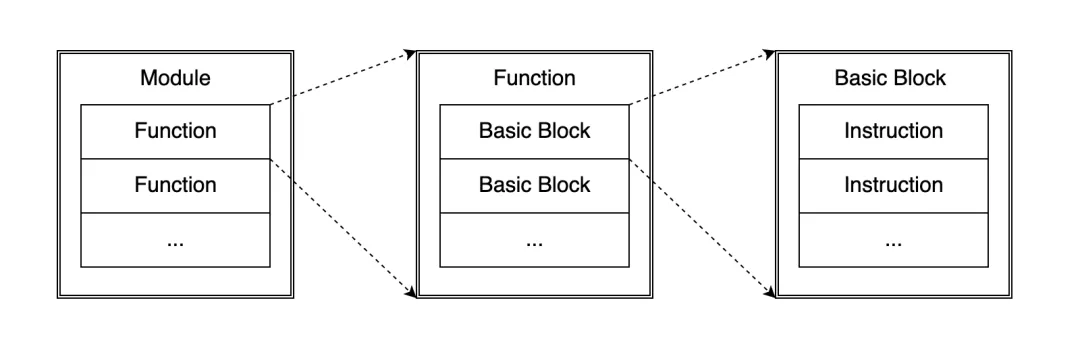
语法书的类型产生后,如果要翻译成底层的汇编代码过程会比较长,并且会比较有难度,因此可以先翻译成 SSA。SSA 比汇编简单,但比 Go 语言要复杂一些。
简单的结构如上图所示。模块中有很多全局函数,函数内部存在很多 Block,Block 中又存在很多指令。
2. Go AST 到 Go ASS
func main() {
fset := token.NewFileSet()
f, _ := parser.ParseFile(fset, "hello.go", src, parser.AllErrors)
info := &types.Info{}
conf := types.Config{Importer: nil}
pkg, _ := conf.Check("hello.go", fset, []*ast.File{f}, info)
var ssaProg = ssa.NewProgram(fset, ssa.SanityCheckFunctions)
var ssaPkg = ssaProg.CreatePackage(pkg, []*ast.File{f}, info, true)
ssaPkg.Build()
ssaPkg.WriteTo(os.Stdout)
ssaPkg.Func("init").WriteTo(os.Stdout)
ssaPkg.Func("main").WriteTo(os.Stdout)
}
Go ASS 的包不在 Go 的标准库中,而是存在于一个扩展库。将上述代码打印后的结果为:
const src = `
package main
var s = "hello ssa"
func main() {
for i := 0; i < 3; i++ {
println(s)
}
}
`
这是解析到 SSA 之前的 Go 的代码片段,只包含一个 main 函数和一个全局的 s。解析到 SSA 后的代码如下:
package hello.go:
func init func()
var init$guard bool
func main func()
# Name: hello.go.main
# Package: hello.go
# Location: hello.go:4:6
func main():
0: entry P:0 S:1
jump 3
1: for.body P:1 S:1
t0 = println("hello ssa -- chai...":string) ()
t1 = t2 + 1:int int
jump 3
2: for.done P:1 S:0
return
3: for.loop P:2 S:2
t2 = phi [0: 0:int, 1: t1] #i int
t3 = t2 < 3:int bool
if t3 goto 1 else 2
上述代码中多了一个 init 函数,这个函数用来进行全局的初始化。main 部分每个「:」代表一个 Block,Block 是 SSA 函数的基本指令容器。
SSA 有一个特点,每个 Block 的尾巴部分都有一个终结指令,必须跳转到另一个 Block 或者返回。这样设计的原因是为了进行后端的优化。
3. Go SSA 的执行和再编译
SSA 可以被解释执行: go/ssa/interp/interp.go
SSA 可以被翻译到 LLVM-IR: tinygo/compiler/compiler.go
八. µGo 案例
今天分享的主题是「Go 编译器定制简介」,这其实有一个本质的问题 —— 为什么是 Go?
曾有一个网红说 Shell 也能开发 Docker,所以 Go 语言其实是个垃圾。这句话看起来有一定的逻辑,但仔细想想既然 Shell 也能开发 Docker,那为什么没有开发出来,而是 Go?可能有人会说是运气,但运气的背后肯定也有着它自身存在的优势:
Go 语言够简单, 25 个关键字
Go 语言的 go/* 包太好用
少是指数级的多 (Less is exponentially more)
因此 Go 社区诞生了很多衍生的定制语言
在 Go 语言发布十周年时我写过一篇文章,叫《Go 十年奋进》,其中提到未来十年,希望国内的 Gopher 可以“Go”的更远,其实某种程度上已经做到了,我们已经到达了定制的层面,Go+的出现就是一个很好的证明,也说明我们已经有很大的用户基础。
μGo 是另一个案例。µGo 是 Go 语言的子集(不含标准库部分), 可以直接作为Go代码编译执行。
func main() {
for n := 2; n <= 30; n = n + 1 {
var isPrime int = 1
for i := 2; i*i <= n; i = i + 1 {
if x := n % i; x == 0 {
isPrime = 0
}
}
if isPrime != 0 {
println(n)
}
}
}
安装: go get github.com/chai2010/ugo
执行: ugo run hello.ugo
具体的代码不做展开,我们来看一下它的架构。
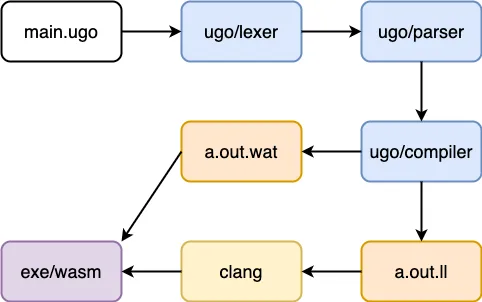
μGo 的架构和 TinyGo 很像,但更小一些。在语法解析后没有类型解析,也没有类型的检查,直接进行 compiler。整个的流程只要代码是 ok 的,就可以先执行出来产生代码,然后再进行完善。目前还在初级阶段。
参考链接
https://www.sigbus.info/compilerbook
Reflections on Trusting Trust - by Ken Thompson
《µGo 语言实现(从头开发一个迷你 Go 语言编译器)》
《Go 语法树入门——开启自制编程语言和编译器之旅》

上面是我近期在编写的两本书。其中语法树入门大概在春节前后会出版,µGo 正在实现的过程中。

在此特别感谢 lan 大佬给我们背书,也感谢许大提供这个分享机会,希望国内能有更多同学关注这个领域。下图是 2002 年许大赠的一本《Go 语言编程》。

