
当 AI 学会“看”世界:多模态大模型推理带你解锁图像理解新能力
近期,谷歌 DeepMind 发布 Gemini 2.5 Pro Preview 'I/O edition',一举夺下 LMArena 和 WebDev Arena 榜首。这一进展不仅展示了 AI 编程能力的跃升,更预示着 AI 正从文本世界走向“可视化时代”。
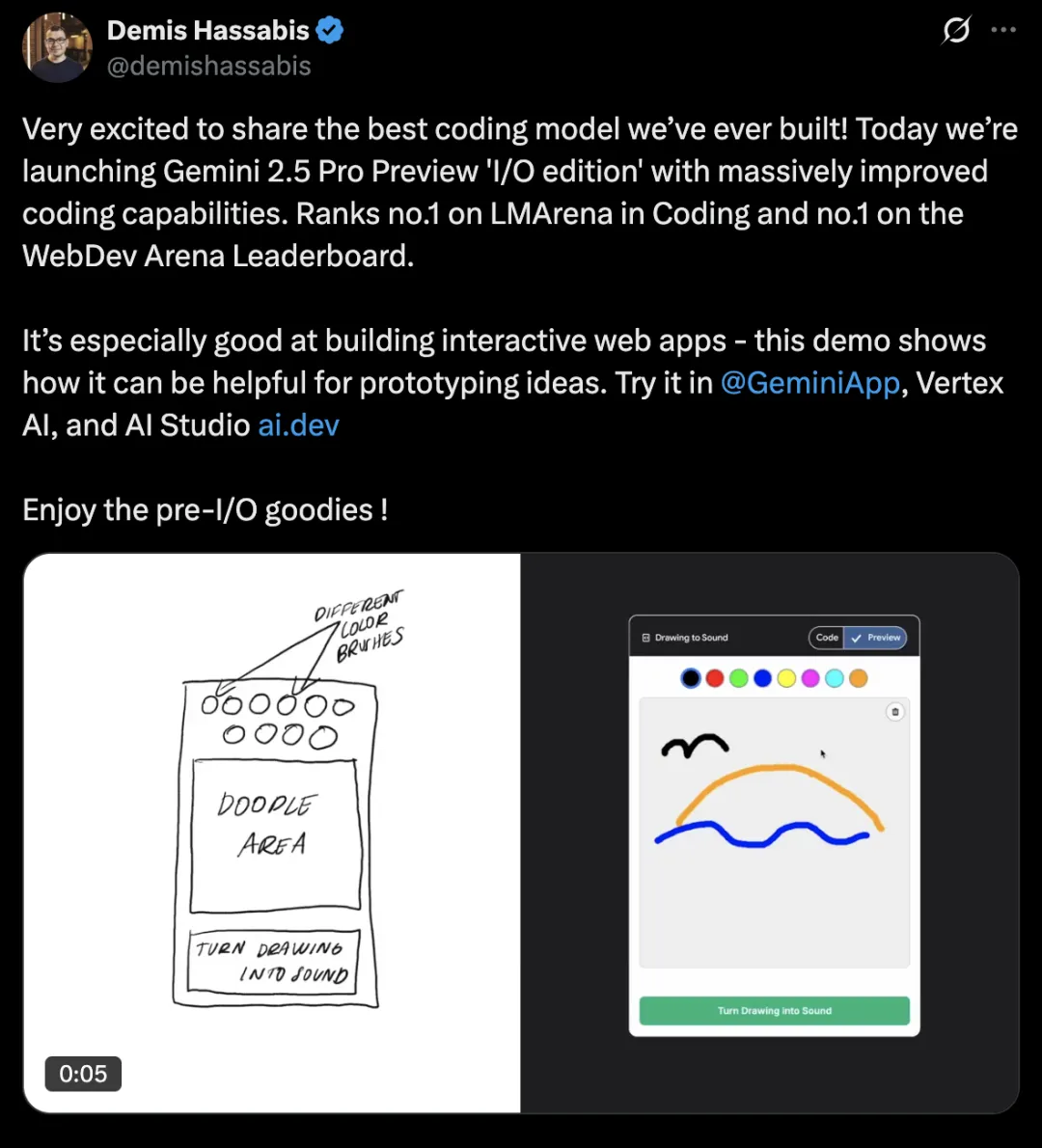
今天,AI 已不再局限于语言助手。它能“看见”图像、“聆听”音乐,跨模态理解信息。这是多模态 AI 的崛起,也是 AI 应用场景进一步拓展的新拐点。
当 AI 学会“看”世界,能做些什么?
视觉内容解析:从图片中提取信息已不新鲜,关键在于理解图片中的上下文关系。例如,一张行业报告截图,AI 不仅能识别文字,还能解读图表数据,提炼关键信息。
基于图片的智能问答:上传图片后,向 AI 提问关于这张图片的任何问题。比如,“这道菜叫什么?”AI 能从视觉信息中快速给出答案。
图像内容搜索:不止文字检索,AI 还能通过图像找到相似款式的商品、辨别植物种类,甚至从成千上万张图片中锁定目标对象。
视觉驱动创作:以图生文,AI 基于图片生成文本、诗歌、短文,甚至为设计师提供灵感建议,将视觉信息转化为创意表达。
七牛云 AI 大模型推理服务(Token API)平台,一站式集成多模态能力
七牛云深耕音视频领域多年,长期陪伴广大开发者和企业探索 AI 应用落地场景。基于在海量数据存储、音视频多媒体服务、高性能计算等领域的长期技术积累,我们构建了强大的 AI 大模型推理服务(Token API)平台,提供开箱即用的多模态能力。
弹性计算:支持自动扩容和负载均衡,开发者无需关注底层架构,专注业务逻辑。
统一 API 接口:一站式接入图片理解、视觉问答、图文生成等多模态能力,降低开发门槛。
性能优化:分布式推理引擎优化,保障大流量并发时的稳定响应。
持续升级:AI 大模型推理服务(Token API)平台紧跟前沿模型技术,模型库定期扩展更新。
当前,七牛云 AI 大模型推理服务(Token API)平台已集成多款多模态大模型:
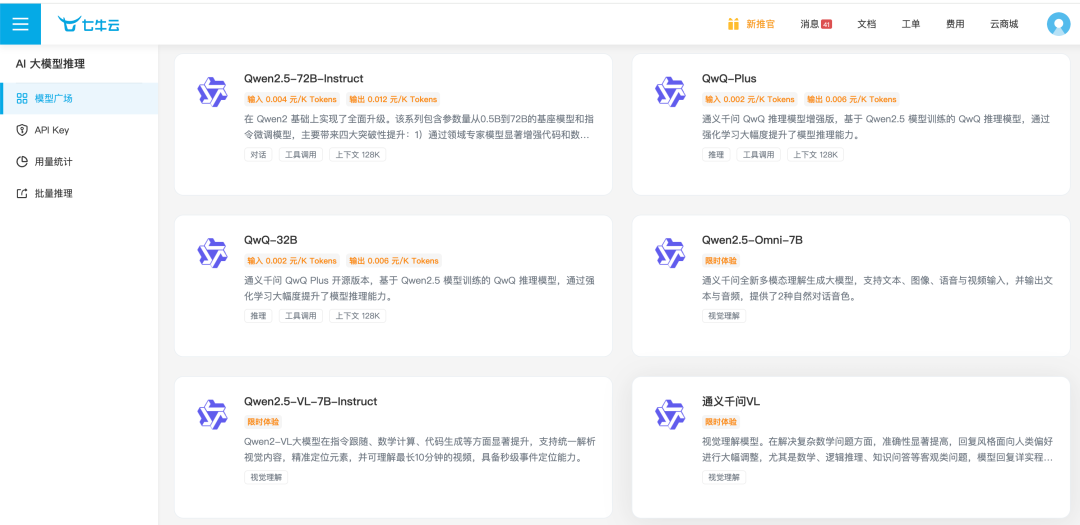
Qwen2.5-Omni-7B:通义千问全新多模态理解生成大模型,支持文本、图像、语音与视频输入,并输出文本与音频,提供了 2 种自然对话音色。
Qwen2.5-VL-7B-Instruct:在指令跟随、数学计算、代码生成等方面显著提升,支持统一解析视觉内容,精准定位元素,并可理解最长 10 分钟的视频,具备秒级事件定位能力。
通义千问 VL:视觉理解模型。在解决复杂数学问题方面,准确性显著提高,回复风格面向人类偏好进行大幅调整,尤其是数学、逻辑推理、知识问答等客观类问题,模型回复详实程度和格式清晰度明显改善。
Doubao-1.5-Vision-Pro:全新升级的多模态大模型,视觉理解、分类、信息抽取等能力显著提升,并重点增强了解题、视频理解等场景的任务效果。支持 128k 上下文窗口,输出长度支持最大 16k tokens。
从“看”到“懂”,多模态 AI 时代的全面进化
多模态 AI 的崛起,不仅赋予 AI “看见”世界的能力,还让其具备跨模态理解、推理的能力。七牛云 AI 大模型推理服务(Token API)平台助力广大开发者和企业快速引入多模态大模型推理能力,解锁更多生成式 AI 应用场景。
未来已来,您准备好迎接多模态 AI 时代了吗?
