
最强编码模型 Claude 4 震撼发布
2025 年 5 月 22 日,Anthropic 正式发布 Claude 4 系列大模型,包括旗舰款 Claude 4 Opus 和高性价比版本 Claude 4 Sonnet,在推理能力、任务执行、上下文处理与工具调用等方面实现了全面跃迁。
本次升级不仅在多个评测中刷新纪录,更通过真实案例展示出 Claude 作为智能体的稳定性与持续任务执行能力,令人印象深刻。
Claude 4 有多强?从评测到实战的全面进化
相较于 Claude 3 系列,Claude 4 的最大特点是:推理更稳,状态保持更强,复杂任务的整体执行力显著增强。
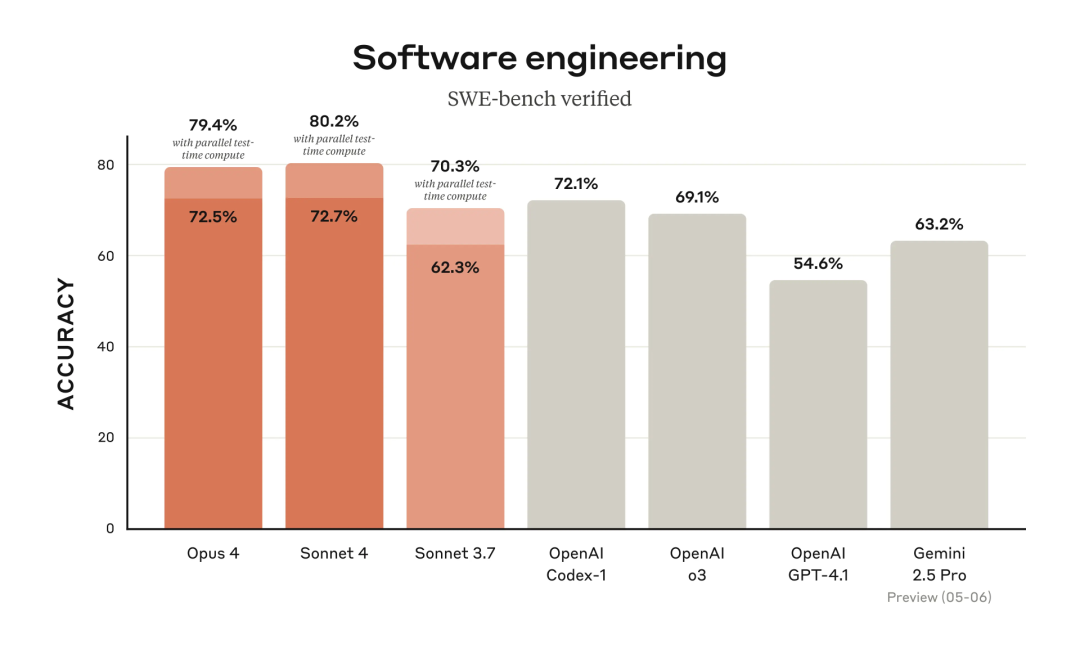
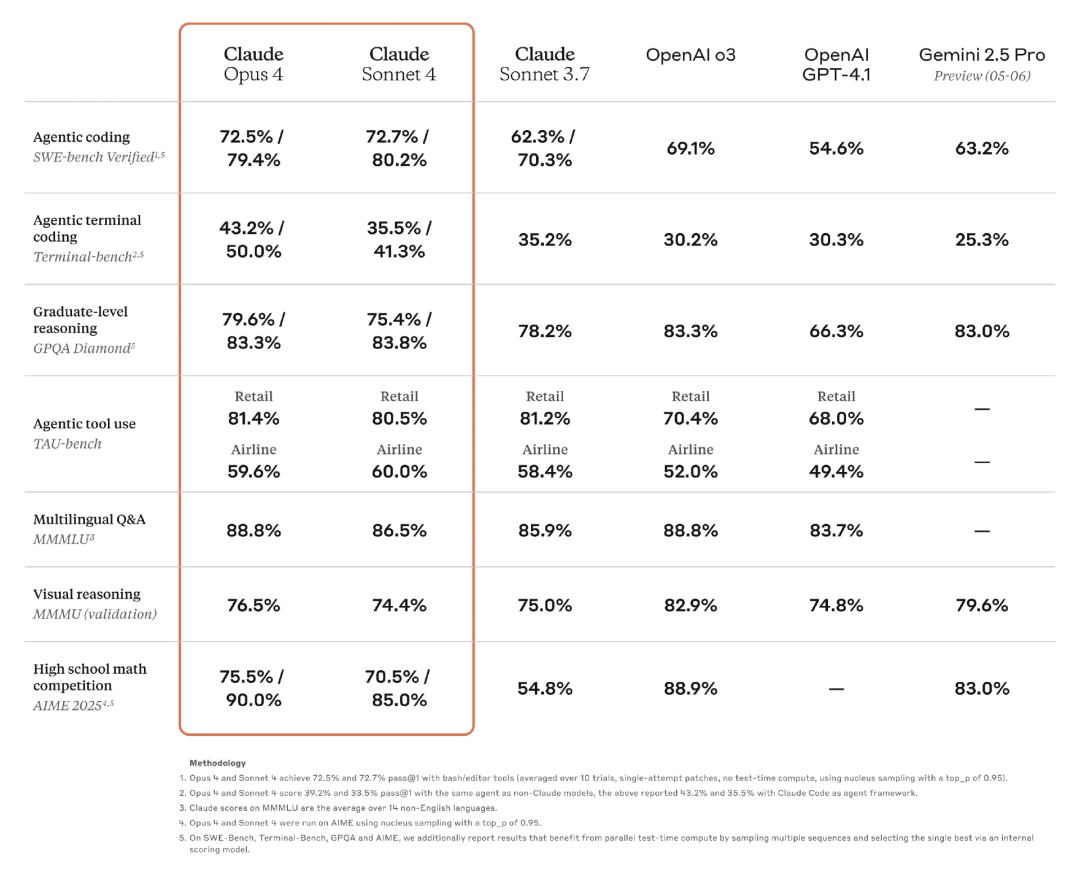
在权威评测中,Claude 4 Opus 交出了一份出色的成绩单:
SWE-bench(软件推理)得分达 72.5%,明显优于 GPT-4 Turbo(65.7%)与 Gemini 1.5 Pro(63.9%)
HumanEval(代码生成)得分 84.9%
MMLU(通识测试)得分 86.8%
在 LMSYS Arena Elo 排名中跃居总榜首位
这些评测并不只是数字游戏,它们指向 Claude 在真实多轮任务中的关键优势:它更懂你在做什么,也更能记住目标、逐步完成复杂流程。
AI 玩游戏?Claude 4 打宝可梦实录展示智能体潜力
为了验证 Claude 4 在复杂任务环境中的实际表现,Anthropic 做了一个大胆的实验:让 Claude Opus 4 自主游玩经典游戏《宝可梦:红版》。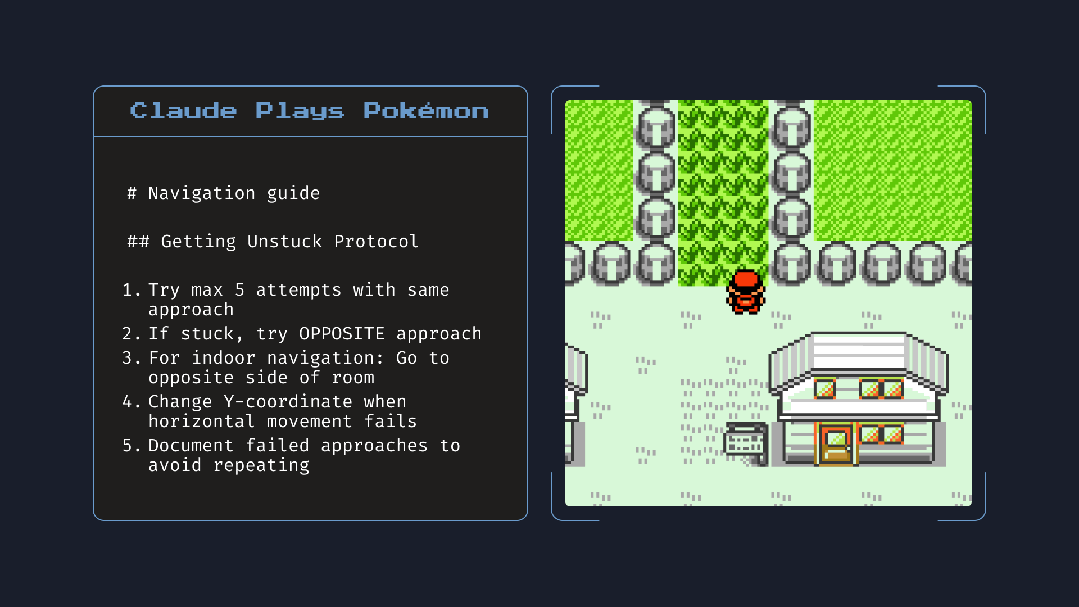
模型通过接收游戏画面图像,并以文本方式操控游戏指令,完整进行了超过 4 小时的游戏进程,涵盖了地图探索、战斗策略、资源管理、任务推进等多个维度。
这不仅是一次娱乐化的演示,更是对 Claude 多模态能力、长期状态保持、目标管理与上下文推理等能力的严苛测试。模型不仅能识别当前情境,还能记住目标任务,在几次战斗失败后自行总结经验、调整策略、选择训练与回补流程,展现出准-Agent 化的行为模式。
这项实验,实际上是一场对未来 AI 智能体「环境适应 + 自主决策」能力的现实演练。
Claude 4 Sonnet:效率与智能的最佳平衡点
如果 Opus 4 是 Anthropic 的“全力出击”,那么 Sonnet 4 则是更适合日常使用的主流型号。它的推理能力接近 Claude 3 Opus,但推理速度更快、资源消耗更低,在高频使用和交互式任务中表现尤为出色。
Sonnet 4 在 SWE-bench 上的得分甚至达到 72.7%,与 Opus 相差无几,远高于同级别主流模型。这让它成为一个性能与成本之间的理想选择,特别适合嵌入工具链、轻量级 Agent 与对话助手场景。
工具调用、文件上下文与记忆系统全面开放
Claude 4 不仅仅是语言模型,更是面向 AI 工具链的基础设施。这次升级显著增强了三个关键能力模块:
Tool Use 工具调用:支持复杂函数编排,能根据上下文需求主动调用多个工具、处理中间结果并生成综合响应。
文件上下文支持:用户可以上传文档(如 PDF、图像、代码文件)作为上下文供模型参考,实现更贴近实际工作流的交互体验。
Memory 长期记忆功能:Claude 4 能跨会话记住用户的偏好、身份信息与长期目标。目前正在逐步向 Claude.ai 用户开放。
这些能力,使 Claude 4 更接近一个「真正理解用户上下文、具备状态意识、能够逐步协作」的智能助手,远不止是一个对话模型。
写在最后:Claude 4 的意义是什么?
Claude 4 并不是一次“算力加强版”的模型更新,而是一种更实用、更智能、更面向长期任务的 AI 能力体现。
它可以写代码、总结论文,也可以制定计划、打游戏。它不只是一个语义引擎,更开始表现出状态管理者、任务执行者、工具调度者的潜质。
这种从「语言模型」向「智能体」的过渡,正是 2025 年 AI 技术进化的主旋律。
Claude 4 的发布,无疑将成为推动这场演进的重要里程碑。
参考内容:
https://www.anthropic.com/news/claude-4
