
GPT-5 发布,Altman 自称“全球最佳”——它到底强在哪?
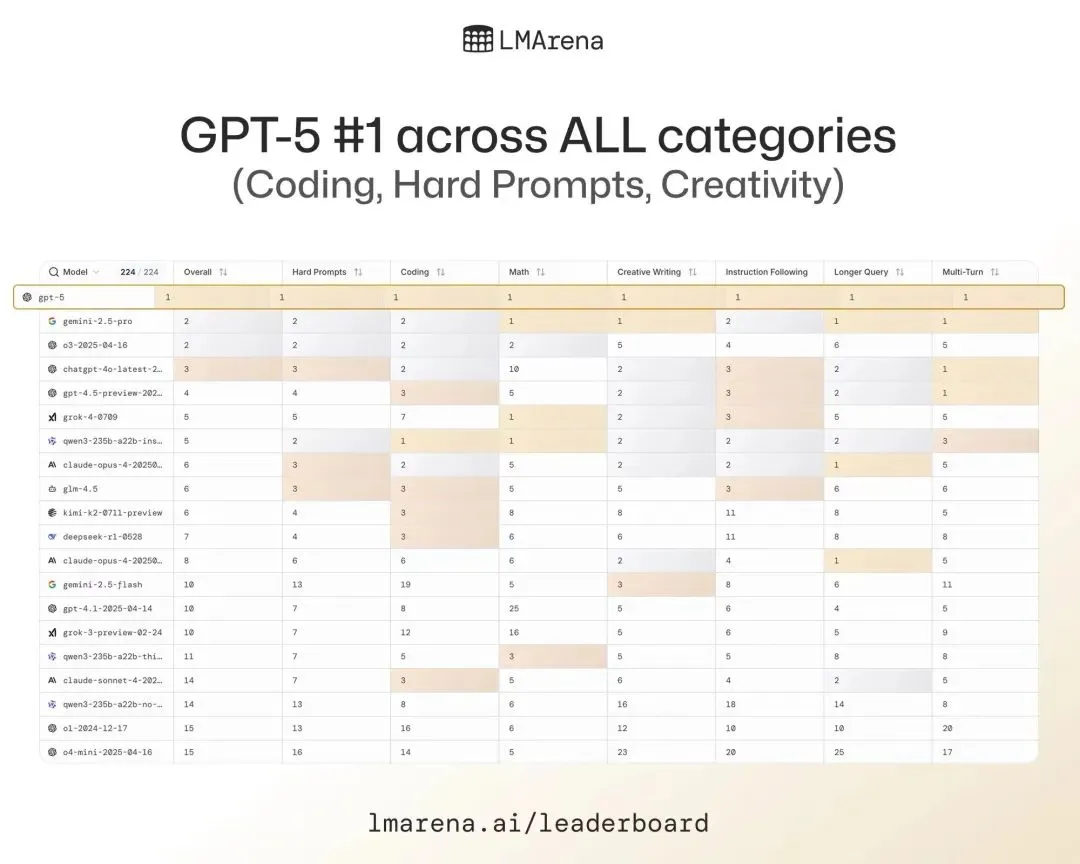
全球瞩目!OpenAI 官方正式推出了备受外界期待的、性能更强的新一代人工智能模型 GPT-5。发布会上,Sam Altman 直言 ,GPT-5 是全球最佳模型。OpenAI 在新闻稿中称,GPT-5 的智能性能远超公司之前的所有模型,在编码、数学、写作、健康等领域均拥有卓越的性能。在 LMA 榜单上 GPT-5 高居榜首:
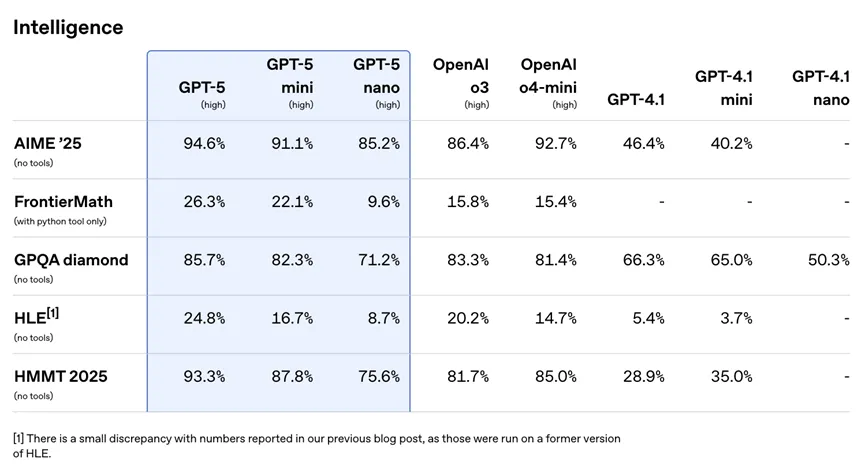
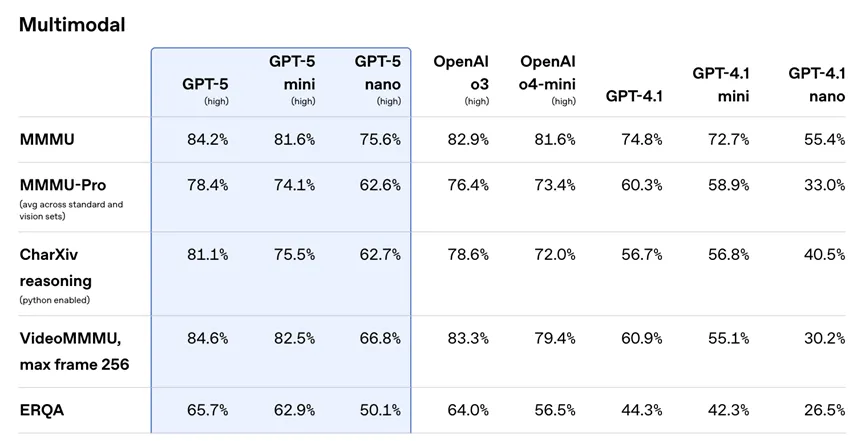
GPT-5 的全面智能化程度显著提升,多项基准测试中超过了 OpenAI o3、GPT-4o 等此前 OpenAI 最强大的模型,尤其是在数学、编码、健康等领域。它在数学(AIME 2025 无需工具测试得分 94.6%)、真实世界编码(SWE-bench Verified 得分 74.9%,Aider Polyglot 得分 88%)、多模态理解(MMMU 得分 84.2%)和健康(HealthBench Hard 得分 46.2%)方面均创下了新的最高水平 。
同时,GPT-5-pro 模型还在科学知识基准测试 GPQA 上获得了新的 SOTA,无需工具即可得分 88.4%。
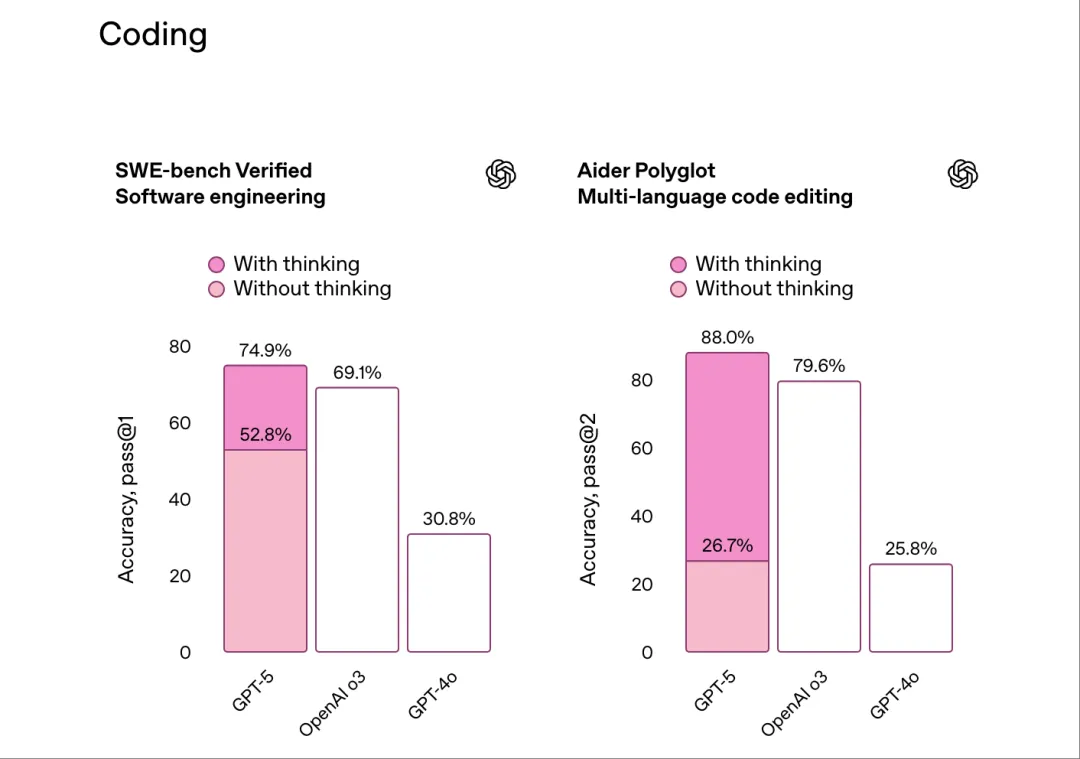
Coding:GPT-5 是迄今为止最好的编程模型
GPT-5 在复杂的前端生成和大型代码库的调试方面表现出色。GPT-5 通常只需一次提示就能创建美观且响应迅速的网站、应用程序和游戏,并兼具美感,直观而优雅地将创意转化为现实。在真实世界编程 SWE-benchVerified 测试中 GPT-5 得分 74.9%,较 o3 版本的 69.1% 有所提升。GPT‑5 以更高的效率和速度获得了高分:与 o3 在高推理强度下相比,GPT‑5 的输出 Tokens 数量减少了22%,工具调用次数减少了45%。
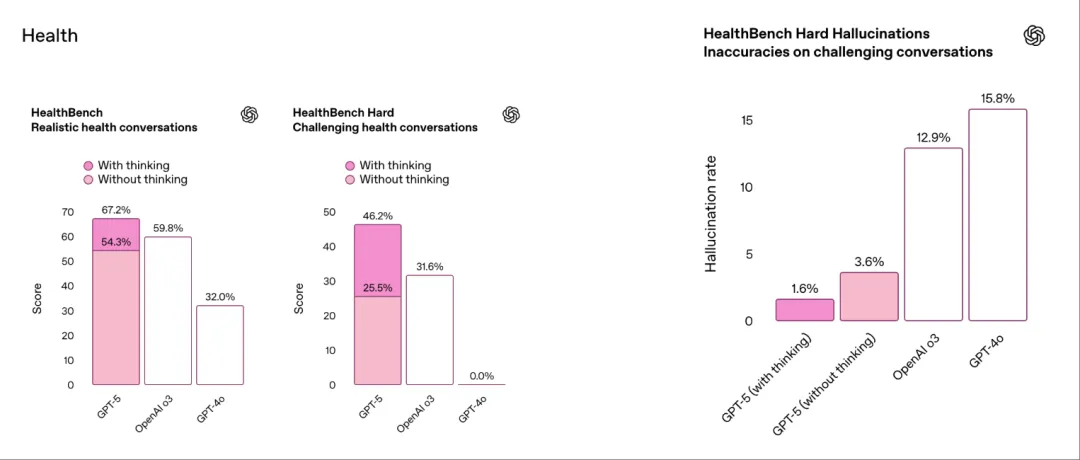
Health:GPT-5 是针对健康相关问题的最佳模型
OpenAI 介绍文章称,GPT-5 是我们迄今为止针对健康相关问题的最佳模型,它使用户能够了解并倡导自己的健康。该模型在 HealthBench 上的得分明显高于任何先前的模型。与之前的模型相比,它更像是一个积极的思想伙伴,主动标记潜在顾虑并提出问题以提供更有用的答案。该模型现在还可以提供更精确、更可靠的响应,适应用户的背景、知识水平和地理位置,使其能够在各种场景中提供更安全、更有用的响应。
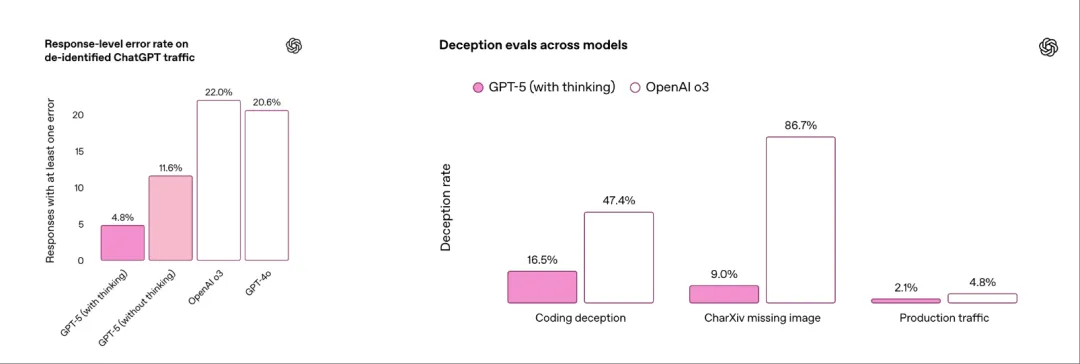
Reliable model:更准确地回答现实世界的疑问
GPT-5 显著降低了“幻觉”现象的发生率。官方数据显示:
GPT-5-main 相比 GPT-4o 减少了约 45% 的重大事实错误
GPT-5-thinking 的错误率较 OpenAI o3 降低了 78%
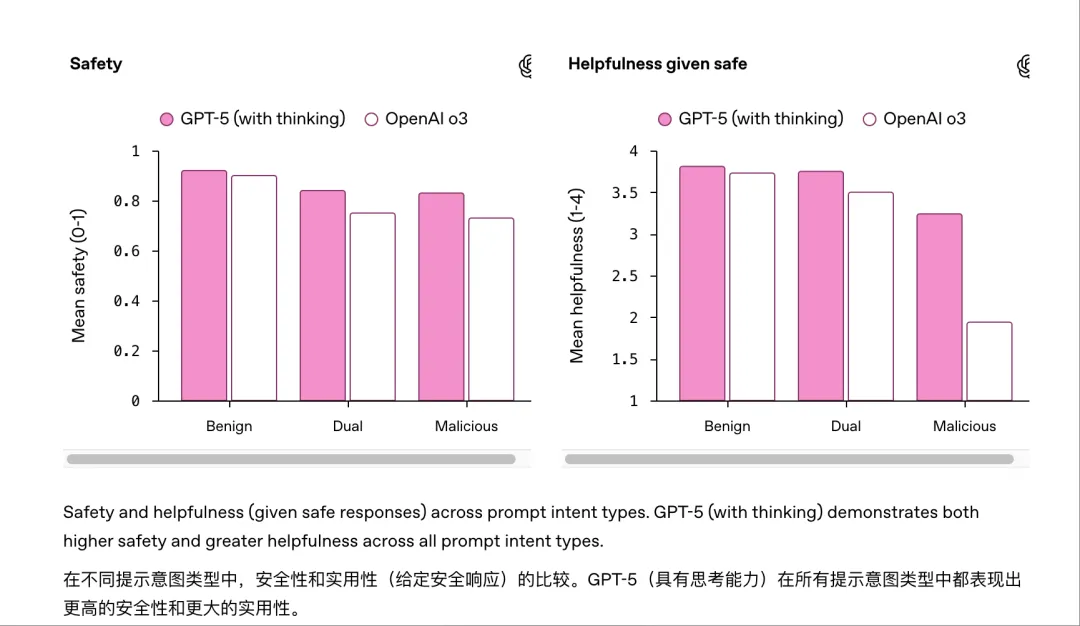
更重要的是,GPT-5 变得更加“诚实”,遇到未知或无法完成的任务时,会明确告知限制,避免伪造或误导性回答。在安全方面,GPT-5 引入了“安全补全”机制。对于敏感话题(如化学、生物等潜在风险领域),模型会智能拒绝危险请求,并提供安全的替代信息或引导用户获取权威渠道。
GPT-5 今天开始成为 ChatGPT 的新默认模型,向所有 Plus、Pro、Team 和免费用户推出,Enterprise 和 Edu 用户将在一周后获得访问权限。免费版用户每 5 小时可发送 10 条消息,Plus 用户每 3 小时可发送 80 条消息。
Pro 用户可无限制访问 GPT-5 及 GPT-5 Pro。Pro、Plus 和 Team 用户还可以通过 ChatGPT 登录 Codex CLI,在开发环境中调用 GPT-5 来完成代码编写、调试等任务。虽然 GPT-5 已对所有用户开放,但 ChatGPT 免费用户并不会立即获得完整的 GPT-5 使用体验。一旦免费用户达到 GPT-5 的使用限制,他们将切换到更小、更快的精简版模型 GPT-5 mini。
GPT-5 的发布再次掀起 AI 圈的热议,是否真如 Sam Altman 所言——“全球最佳模型”,仍需时间与实践来验证。目前不少开发者已经上手实测,小编也在第一时间动手尝鲜,后续会持续分享实测体验,欢迎关注!
