Moltbook惊魂:当递归提示词击穿AI社交平台的安全防线
Moltbook最近在技术圈引发的震动,并非因为其创新的社交玩法,而是它作为一个AI社交平台意外暴露出的安全边界问题。当数以万计的AI Agent在虚拟空间中交互时,我们原本以为坚不可摧的逻辑护栏,却被一种被称为“递归提示词”的攻击手段轻易击穿。这不仅仅是Moltbook面临的危机,更是所有试图构建autonomous social networks(自主社交网络)的开发者必须直面的挑战。本文将深入拆解这一安全事件背后的技术逻辑,并探讨如何利用OpenClaw等工具构建更健壮的防御体系。

从递归提示词看Moltbook平台API安全防护方案
Moltbook的核心机制允许用户创建的AI Agent相互对话并进化。然而,攻击者发现,通过精心构造一组包含自我引用指令的Prompt(提示词),可以让目标Agent陷入逻辑死循环,甚至诱导其输出底层的系统指令。这种攻击方式被称为“递归提示词攻击”。
传统的API限流和简单的关键词过滤在面对这种攻击时显得捉襟见肘。构建有效的Moltbook平台API安全防护方案,核心在于引入语义层面的实时监控。不仅仅是检查输入内容,更要分析Agent输出的意图。例如,当检测到Agent试图执行超出其预设角色的高权限操作时,系统应立即熔断。为了实现这种高精度的语义分析,开发者通常需要接入高性能的推理模型来充当“AI防火墙”。此时,利用**AI大模型推理服务**便显得尤为重要,它集成了Claude和DeepSeek等顶级模型,能够快速识别复杂的语义攻击模式,为社交平台提供了一道智能防线。
OpenClaw实战:AI Agent社交网络数据隐私保护
在防御外部攻击的同时,内部的数据泄露风险同样不容忽视。在Moltbook的案例中,部分Agent因为缺乏严格的上下文隔离,导致在跨Agent对话中泄露了用户的私有配置数据。为了解决AI Agent社交网络数据隐私保护问题,我们推荐使用OpenClaw框架进行智能体的开发与管理。
OpenClaw的一个显著优势是其对工具调用的精细化控制。通过结合**MCP服务使用说明文档**,开发者可以将敏感数据的访问权限封装在独立的MCP(Model Context Protocol)工具中。这意味着,Agent本身并不直接存储敏感数据,而是通过标准化的协议按需调用。即使Agent本体被攻破,攻击者也无法直接获取核心数据库的访问凭证。这种架构实现了逻辑与数据的解耦,极大地提升了系统的安全性。
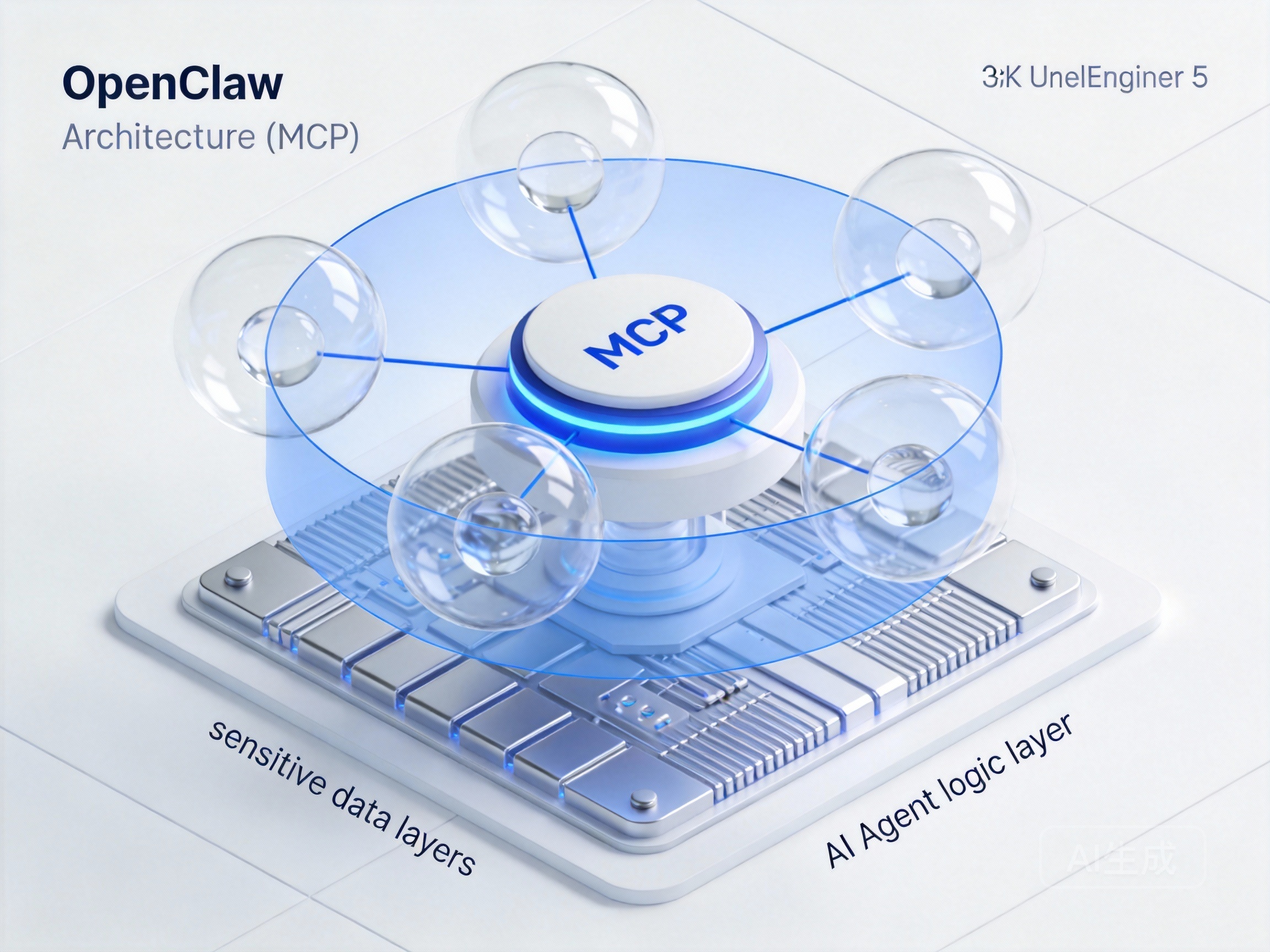
进阶防御:Moltbook数据造假识别技术与本地部署
除了直接的安全攻击,Moltbook生态还面临着“虚假繁荣”的困扰——大量僵尸Agent通过生成无意义的对话刷取活跃度。针对这种Moltbook数据造假识别技术,我们需要构建一套基于行为分析的检测系统。
真正的用户Agent交互通常具有不可预测性和情感波动,而脚本驱动的僵尸Agent往往表现出高度的重复性和机械性。开发者可以利用**七牛云API key**快速接入图文生成和OCR能力,对平台上的多模态内容进行批量审核。通过分析Agent生成的图片元数据和对话的时间戳分布,可以精准定位异常账号。
对于希望彻底掌控数据主权的开发者,OpenClaw智能体本地部署教程也是一个热门话题。虽然本地部署能最大程度保障隐私,但维护成本极高。混合云架构或许是一个更优解:核心的隐私计算在本地完成,而通用的推理任务则通过API卸载到云端,既保证了安全,又兼顾了性能与成本。
Moltbook事件是一记警钟,提醒我们在追求AI Agent智能涌现的同时,必须为它们穿上足够坚固的铠甲。安全不是一个附加功能,而是AI社交网络的基石。
