
AI最大的信息差:打破企业级私有知识库搭建壁垒
在技术圈,大家都在谈论 DeepSeek 的崛起和 GPT-4 的能力边界,但真正让一部分人悄悄拉开差距的,其实是AI最大的信息差——如何将通用的超级大脑,驯化成懂业务、守规矩的企业专属参谋。大多数企业还停留在“会用 ChatGPT 写邮件”的阶段,而先行者已经开始着手搭建企业级AI私有知识库,彻底改变了内部信息的流转效率。
这种信息差的核心,不在于你拥有多昂贵的模型,而在于你如何解决通用大模型落地的“最后一公里”难题:数据安全、幻觉控制以及与现有业务流的无缝对接。
告别“一本正经胡说八道”:精准控制生成式AI幻觉
很多开发者在尝试接入大模型时,最头疼的就是生成式AI幻觉。模型虽然能侃侃而谈,但在面对严谨的业务问题时,经常会编造事实。比如询问公司去年的财务报销政策,它可能会给你编造一条看似合理实则完全错误的条款。
解决这一问题的关键在于 RAG(检索增强生成)技术的深度应用,而非单纯依赖模型的预训练知识。通过构建高质量的企业级AI私有知识库,我们可以让大模型在回答问题前,先去企业的专属资料库里“查字典”。

但这不仅仅是把文档扔进数据库那么简单。真正的门槛在于数据的清洗、切片策略以及向量化模型的选择。对于希望快速验证效果的团队,直接利用成熟的云端设施是更明智的选择。例如,灵矽AI 提供的解决方案,就集成了智能知识库和多模型能力,能够帮助企业快速构建高精度的知识检索系统,从源头上大幅降低模型胡言乱语的概率。
MCP协议:AI Agent 爆发的前夜
如果说 RAG 解决了“懂知识”的问题,那么 MCP(Model Context Protocol)协议则解决了“能干活”的问题。这是当前AI最大的信息差中极具技术红利的一环。
传统的 AI 应用开发,往往需要针对每一个工具(如查天气、读数据库、发邮件)单独写大量的胶水代码。而 MCP 协议试图建立一种标准,让大模型像使用 USB 设备一样,插上就能调用各种工具。这意味着,未来的 AI Agent 不再是一个只会聊天的机器人,而是一个能直接操作企业 ERP、CRM 系统的智能员工。
对于开发者而言,掌握MCP协议开发Agent应用的能力,意味着你能够构建出真正的AI工作流自动化系统。想象一下,销售人员只需对 AI 说一句“帮我整理上周意向客户并发送跟进邮件”,AI 就能自动调用 CRM 接口拉取数据,结合知识库的话术生成邮件,并调用邮件服务发送,全程无需人工干预。
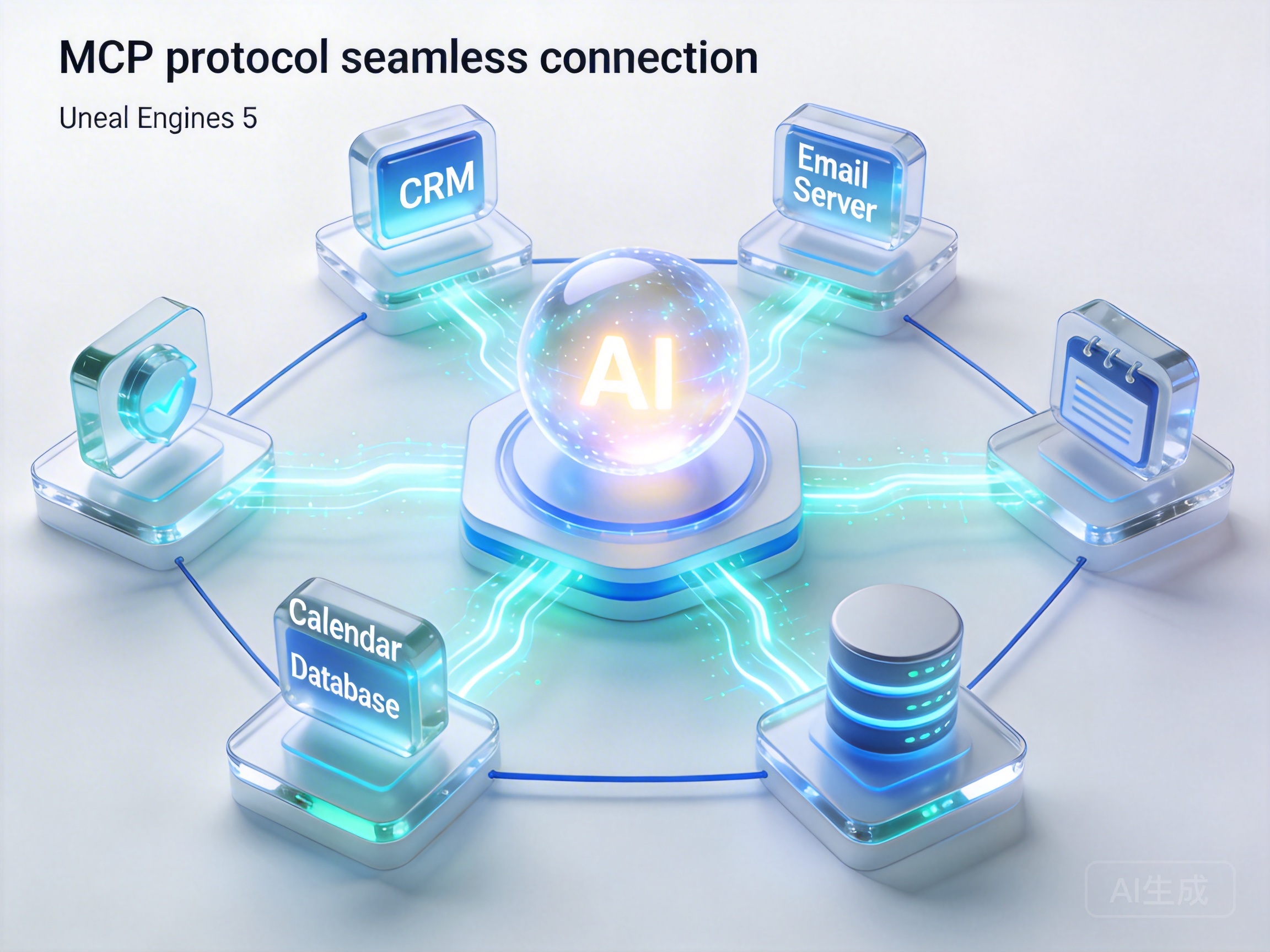
为了降低这种复杂应用的开发门槛,高效AI工作流自动化搭建 变得至关重要。通过标准化的模型能力编排平台,开发者无需在本地痛苦地配置环境,即可快速聚合多工具服务,实现业务逻辑的云端托管。
实战落地:从推理到工作流的闭环
很多技术负责人在寻找企业级AI知识库搭建方案时,往往陷入“自建还是买服务”的纠结。自建 DeepSeek 或 Llama 模型虽然看起来自主可控,但高昂的显卡成本和运维压力往往让人望而却步。
更务实的路径是混合架构:利用高性能的云端推理服务作为核心大脑,配合本地或私有云的知识库作为长期记忆。比如,通过接入**AI大模型推理服务,企业可以直接调用 DeepSeek、Claude 等顶级模型的能力,同时享受兼容 OpenAI API 的便捷性。这种“体验即送 300 万 Token”的低门槛方案,让开发者可以零成本试错,快速验证DeepSeek接入企业工作流教程**中的各种设想。
一旦解决了推理算力和知识库构建,剩下的就是通过 MCP 将两者串联。你需要定义好工具的边界,比如哪些数据模型可以读取,哪些操作模型有权限执行。当这一整套闭环跑通,你会发现,所谓的“AI 焦虑”消失了,取而代之的是实实在在的效率倍增。这才是利用信息差,构建技术护城河的最佳实践。
